Hashimoto laboratory is actively promoting collaborative R&D projects
to apply our latest results to real world problems.
For more information about our research results and collaboration,
please contact Hashimoto by email.
email: mana -at- isl.sist.chukyo-u.ac.jp
3-D Sensing
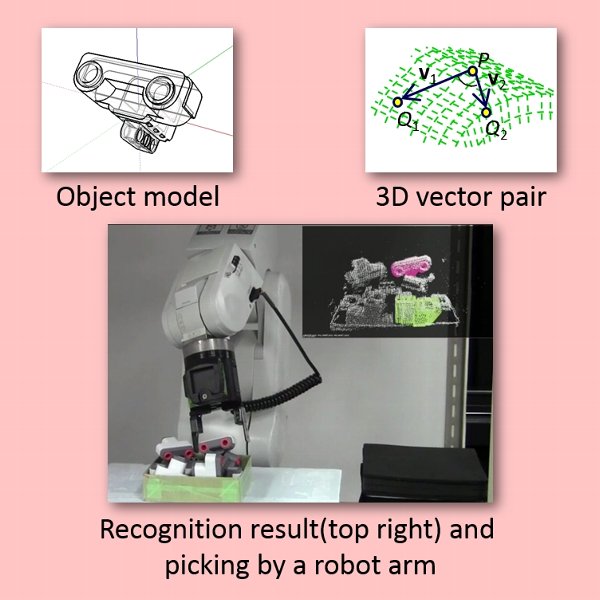
Bin picking with vision utilizing 3D vector pairs
Bin-picking vision that recognizes position and posture of stacked objects was developed. Pre-analyzing the form of a target object and recording characteristic local shapes of parts of objects as model data makes it possible to detect objects at high efficiency.
In this research, two 3D spatial vectors (a “vector pair” hereafter) are set as units of matching, and characteristic vector pairs within the target object are extracted. Multiple vector pairs are collated as input distance data, and location and posture supported by a great number of vector pairs are output. This technology has two benefits: first, the amount of data is very small, so recognition speed is high; second, only characteristic data is used, so the risk of mis-recognition is low. Experimental tests demonstrated recognition success rate of 93.1% in a processing time of 1.36 seconds.
This technology will be applied in fields such as 3D vision systems and object modelling for robots used for assembly operations.
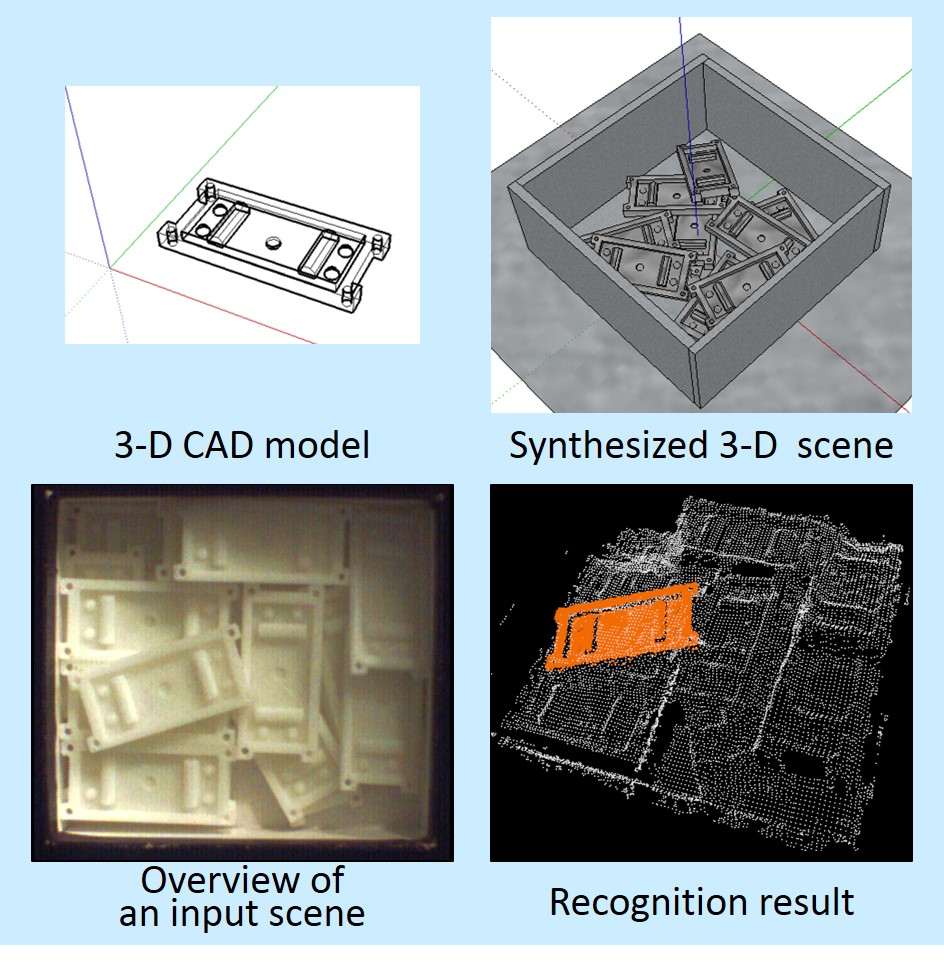
Recognition of bulk objects by using 3D-CG applying feature points
In situations in which objects are arranged in bulk, a robotic-vision method that can reliably recognize objects was developed. It enables high-reliability verification by using only feature values with high discrimination capability selected from an object model.
nput data are predicted by using a physical model and 3D computer graphics (3D-CG) technology, and feature values that might be generated in the input data are created. After that, those feature-value groups are used, and 3D points having feature values with high discrimination capability in a certain feature space are selected as characteristic points from the physical model and used for recognition. As for the developed method, by using vector pairs (namely, a few vector pairs with high discrimination capability) to speed up recognition, it is possible to achieve high reliability and high speed.
The method can be applied to object recognition in complicated situations by, for example, vision systems for industrial robots, in which similar objects are in contact.
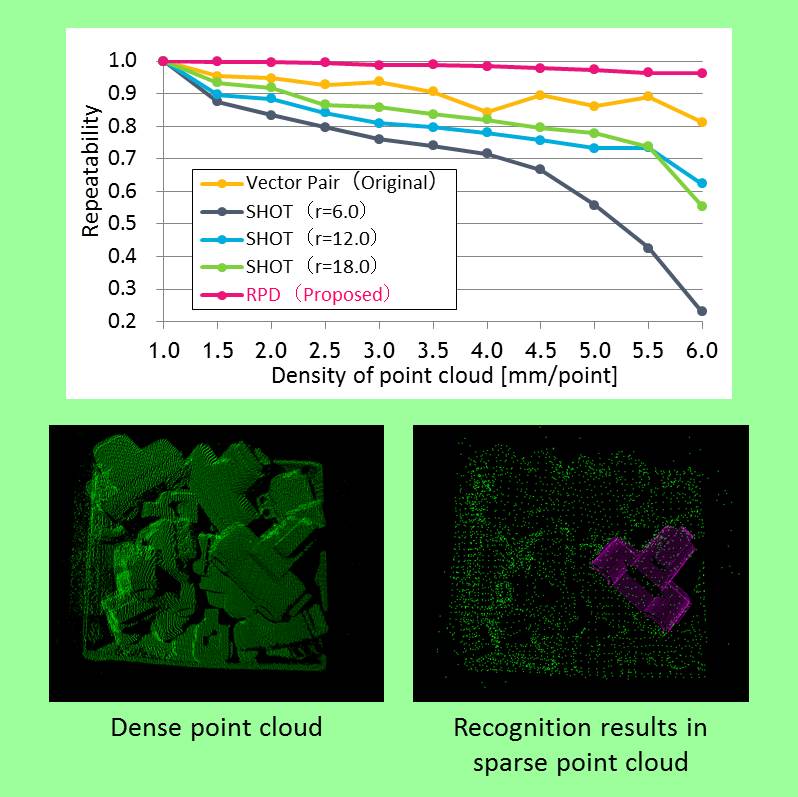
Recognition of objects without dependence of coarseness of 3D point groups
A method that can recognize objects at high reliability—even in the case that the coarseness of the object model and that of the point groups of the input scene differ significantly—was developed.
In this study, which focuses on the fact that the ratio of relative points of local regions is an invariant quantity corresponding to coarseness of point groups, a new feature value, defined as “relative point density” (RPD), is proposed and used for matching. Recognition that is robust against differences in densities of point groups, due to variation in the distance between the 3D sensor and the target object and different measurement methods used by different sensors, was achieved.
RPD can be used for object recognition by vision systems and industrial robots for detecting obstacles around autonomous vehicles.
High-speed and high-reliability object recognition using CCDoN feature values
The feature value proposed in this study combines three shape-evaluation values, namely, two curvature values (calculated in different spherical regions) and a feature value, called “difference of normals” (DoN), calculated from differential values between normal vectors. This feature value is thus called “combination of curvatures and difference of normals (CCDoN).
Since conventional DoN feature values are expressed as relative values calculated from differential values between normal vectors, mistaken collation between feature points with the same relative values might occur.
Given that issue, in the present study, scalar values function in a similar way to DoN feature values, and combining curvature values (which are robust in regard to variations in posture) with DoN makes is possible to improve the reliability of feature values and thus reduce the possibility of mis-collation. Each CCDoN feature value expresses differential values between local forms around feature points, between wide-area forms, and between normals. Utilizing these three different values for collation makes it possible to lower mistaken collation below the error rate for conventional DoN feature values.
CCDoN can be applied to robot vision systems and automatic-assembly systems.
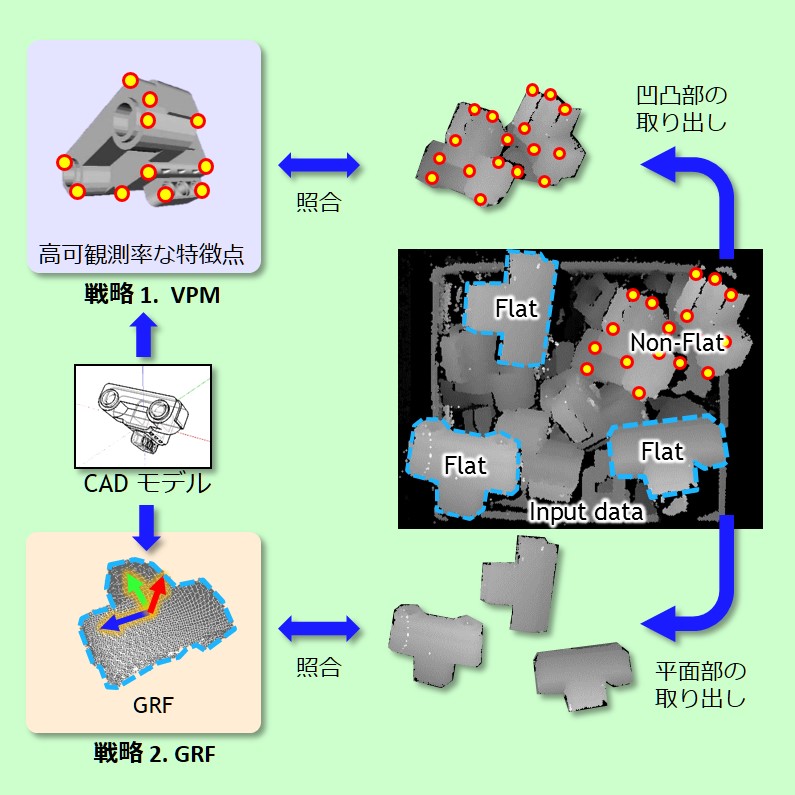
A method for stable 3D object recognition that can even recognize objects with flat surfaces was developed
Although object recognition using 3D feature values is becoming widespread, in the case that the target object for recognition looks like it has a flat surface, it is a problem that feature values at key points are unstable and recognition rate falls accordingly. And because flat surfaces have few characteristic features, this problem is the cause of instability in the reference coordinate system.
Given that issue, in this study, a new reference coordinate system, called “GRF” (global reference frame), which can effectively handle flat surfaces, was developed. By combining the developed GFR with conventional vector-pair mapping (VPM), which is effective in terms of uneven surfaces, object recognition that is independent of the appearance of flatness was accomplished.
On current industrial lines, manufactured products frequently use flat surfaces, so it is anticipated that GRF will provide stable object recognition regardless of the kind of product.
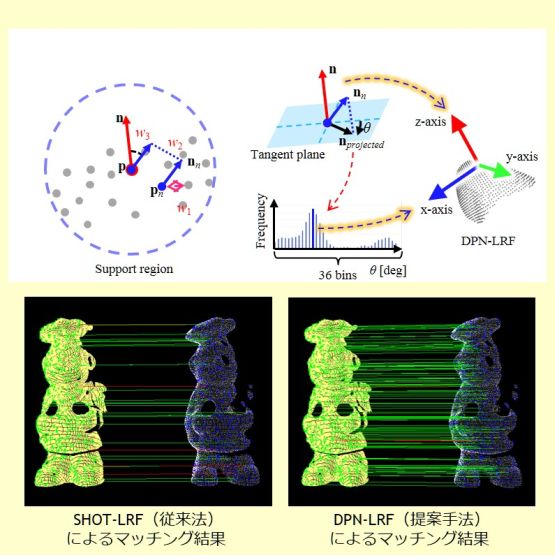
Proposal of a local reference coordinate system that is robust against variation and insufficiency of point-group density (DPN-LRF)
A local reference coordinate system called “DPN” (dominant projected normal)-LRF—which enables reliable matching even if variation or lack of density of point groups occurs—was developed.
A local reference coordinate system, called “LRF (local reference frame), is set for each key point. Up until now, the LRF has been unstable when the densities of point groups of matching targets are different or insufficient, and the problem that key-point matching fails has remained unsolved.
In this study, a method for calculating LRF regardless of this problem was devised and evaluated. Simply replacing LRF with DPN-LRF makes it possible to improve reliability of matching.
It is possible to apply DPN-LRF to object-recognition systems for mobile robots like ones used in the home.
High-speed key-point detection and feature-value description for 3D object recognition
A method for high-speed key-point (feature points) detection and feature-value description for 3D object recognition was developed. This method involves detection of key points on the basis of proportion (occupancy rate) of measurement point groups for local regions and feature-value description using “multi-scale shells” (MSS) in which only the outermost shells of a multi-scale spheres are taken as description regions. The calculation of occupancy rate is equivalent to a simple process that measures scores within local regions, and MSS feature values are defined by using only point groups with limited description regions, thereby achieving outstanding recognition speed. Comparing the performance of this 3D object recognition with that of a conventional method revealed that the recognitions rates are about the same, but the processing speed of the proposed method is about three times that of the conventional method.
This method can be applied to model retrieval such as that incorporated in vision systems for autonomous vehicles and industrial robots.
Human Sensing
Increasing reliability of steady-movement discrimination for detecting steady motion in applications such as toilets for the elderly
Accompanying the increase in the number of elderly people living alone and the decrease in the number of welfare workers, the number of accidents involving the elderly has been increasing. Consequently, systems for automatically detecting unsteady motions that might lead to accidents are being demanded.
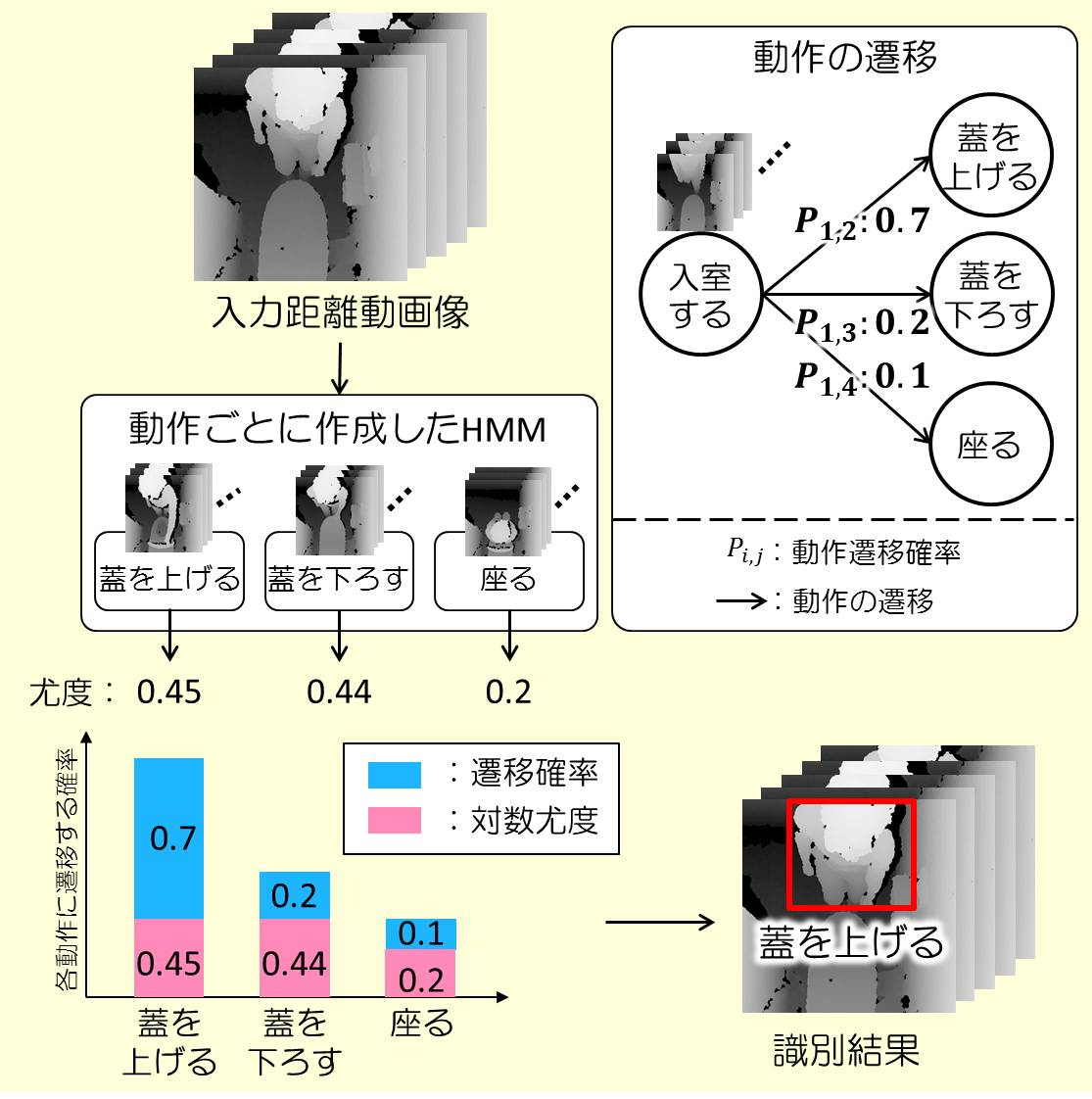
In this study, a method for highly reliably discerning steady motions of elderly people so that unsteady motions can be detected is proposed and applied in the toilets in the homes of elderly people (namely, a place where many accidents occur).
The fact that the order in which movements in people’s daily lives are generated follows patterns created for each movement is focused on, and movement is discriminated in consideration of the ease of transition between movements in addition to the graphical characteristics of each movement. On the basis of hidden Markov models (HMMs), movements are discriminated by using the likelihood output from each HMM and a probability that expresses the ease of transition in an movement space. In this way, even in the case that graphical features are similar, transitions with low possibility (due to differences in the orders of occurrence of movements) are suppressed, and movements can be discriminated at high reliability.
generated follows patterns created for each movement is focused on, and movement is discriminated in consideration of the ease of transition between movements in addition to the graphical characteristics of each movement. On the basis of hidden Markov models (HMMs), movements are discriminated by using the likelihood output from each HMM and a probability that expresses the ease of transition in an movement space. In this way, even in the case that graphical features are similar, transitions with low possibility (due to differences in the orders of occurrence of movements) are suppressed, and movements can be discriminated at high reliability.
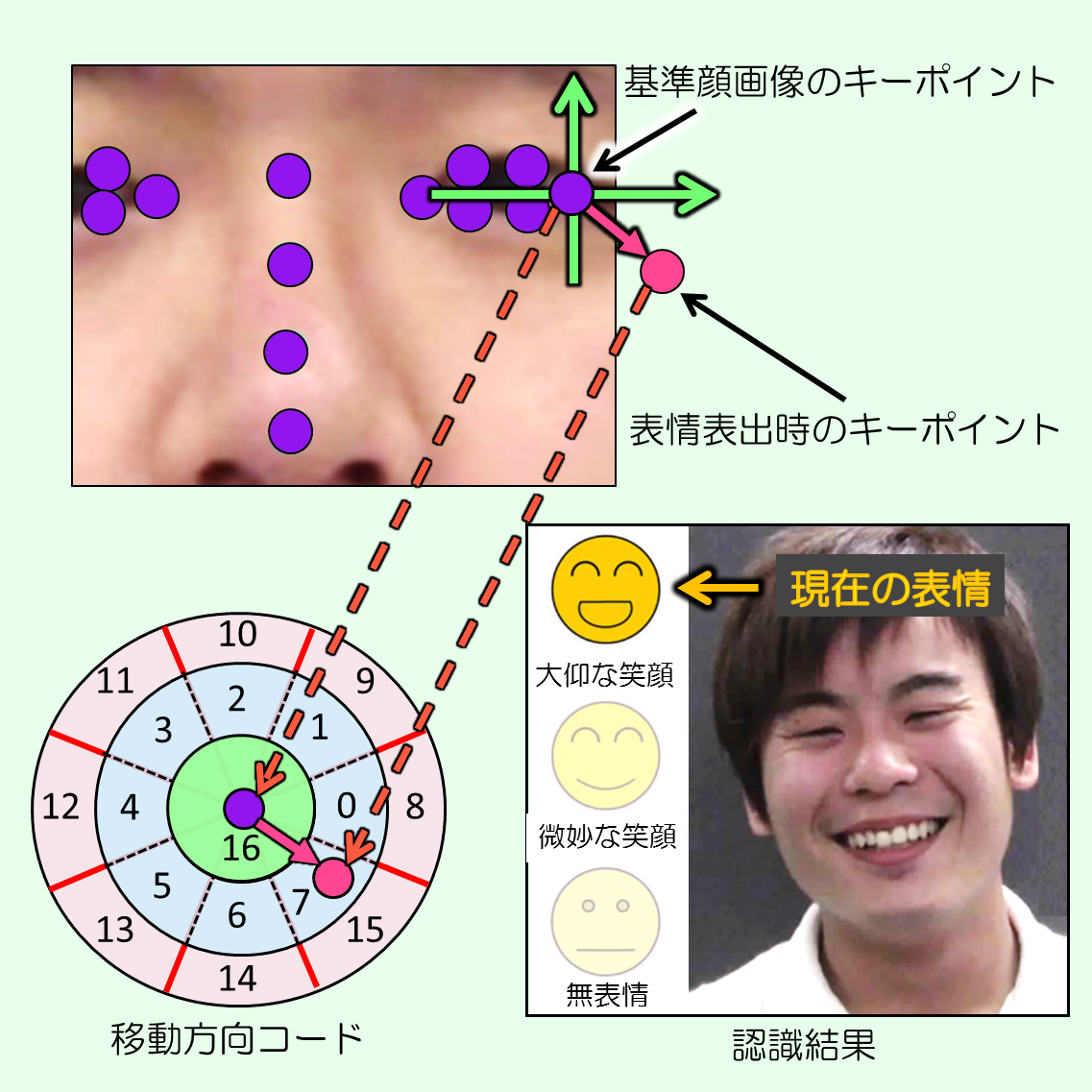
Discrimination of expressions regardless of individual dependence on the basis of a“movement-direction code” for facial key points
To evaluate the quality of services, it is necessary to “read” the extent of the smile on a customer’s face. On that occasion, two problems arise from the standpoint of practicality. The first problem is discriminating grandiose expressions and subtle expressions. The second problem is discriminating the expressions of person who have not been used for training process. In this study, a method for discriminating grandiose expressions and subtle happy expressions that don’t simply depend on learned face data is proposed.
First, key points are extracted from facial features (like the eyebrows and mouth), and direction and extent of movement are calculated from the key points that correspond to standard facial expressions. By means of quantization, each key point is given a “movement-direction code” as a feature value. On the basis of the frequency distribution of the feature values of each facial expression generated from learning images of multiple people, each expression is different, and by selecting feature values shared by an unspecified number of people and using them for discrimination, the two problems stated above are solved.
It is expected that this method will be applied for sensing of feelings of an unspecified number of people in applications such as a tool for TV-program ratings surveys and communication between people and robots.
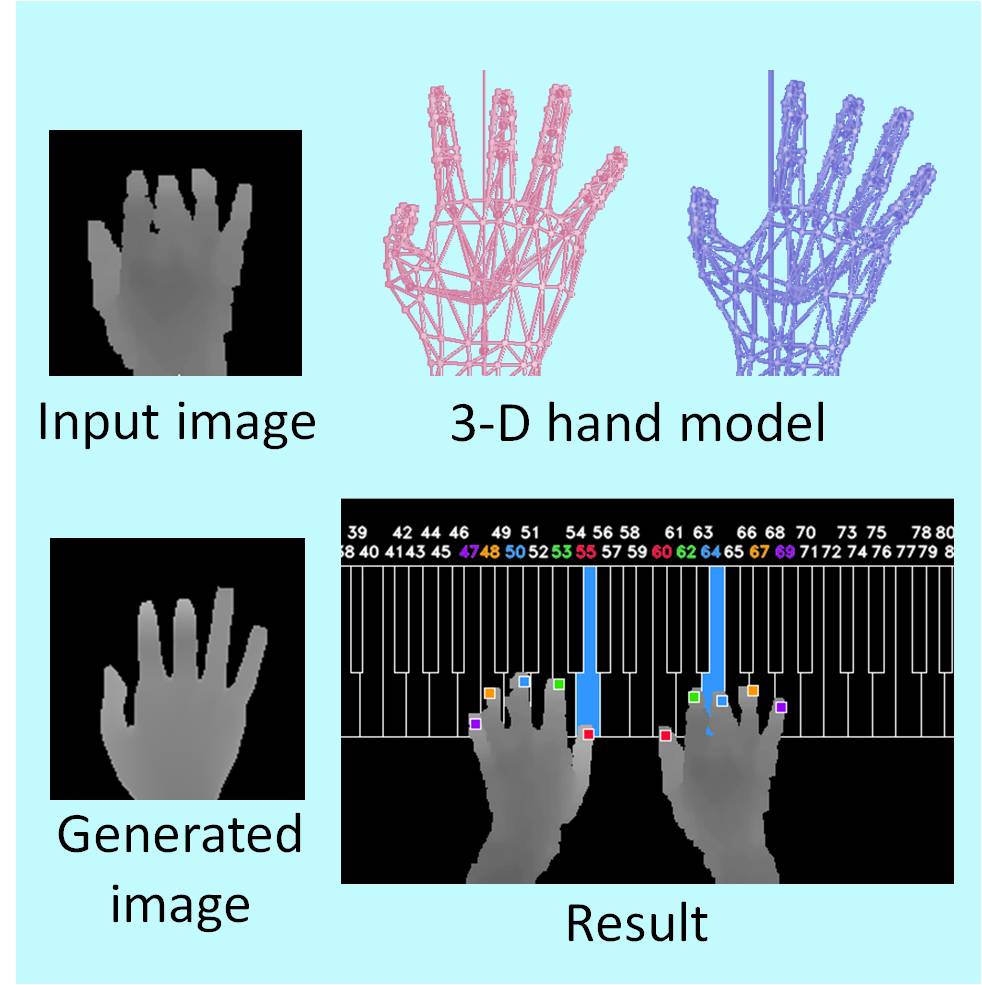
3-D Recognition of Hypothesis-and-Verification piano fingering based on on-line image generation using a 3D hand model
A method for observing piano fingering during a performance without the need for prior learning (which does not use markers and can be used regardless of the performer) was developed.
In this study, a hypothesis-verification approach was taken. A multitude of fingertip-position candidates are detected from range images of the fingers of the piano player, and correspondence with piano keys expressed probabilistically is generated as a hypothesis group. 3D forms of all the fingers are estimated from each hypothesis, and images are created on line by using a general-purpose 3D hand model. By comparing those created images with real input images and collating them, it is possible to determine a maximum-likelihood hypothesis and assess the fingering state. Moreover, in the hypothesis-generation step, by evaluating the naturalness of the fingers in each hypothesis, and narrowing down the hypotheses beforehand, it is possible to improve the efficiency of the processing.
It is expected that this method will be applied for analysis of finger motion in applications such as systems for evaluating the skill of learners playing the piano, user interfaces operated directly by finger motion, and recognition of sign language.
Image Processing
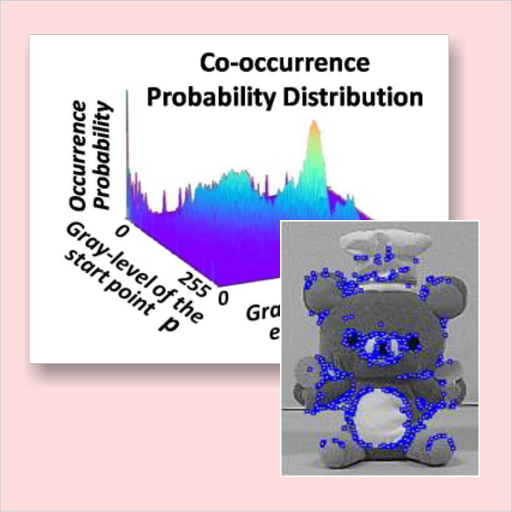
Ultra-high-speed template matching based on gray-level co-occurrence probability (CPTM)
Template matching is a general-purpose method for detecting target objects in an image. In this study, only unique images are picked out automatically from within all pixels included in the template image; as a result, ultra-high-speed matching using only an extremely small amount of data is possible.
The probability of co-occurrence of image patterns from plural images is calculated, and it is considered that the patterns get more unique as the probability decreases. It was conformed that by means of CPTM, image-processing speed is increased 170 times in comparison with that of conventional matching, even though only a small proportion (0.6%) of the images within the template are used, while recognition rate of almost 100% was achieved.
CPTM can be applied in a fields ranging from component inspection on productions lines, assembly robots, and high-speed tracking of people and target objects.
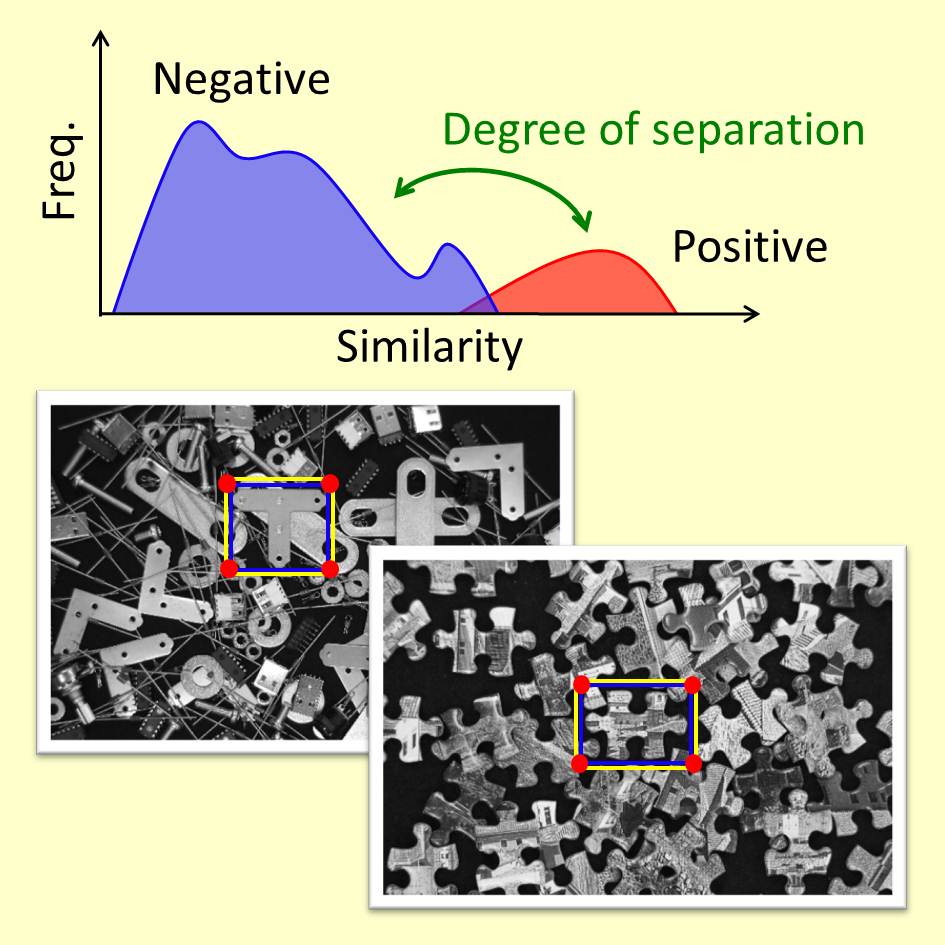
Image matching that maximizes isolation of similar surrounding objects
As part of the advancement of image-selection matching (which is descended from CPTM), template matching that cannot be fooled by disturbing objects with similar shapes is being developed. By preparing detected target objects (“positive samples”) and objects with similar shape (“negative samples”) in advance, it is possible to extract images that are included in common in the positive samples but are almost invisible in the negative samples.
In this study, the problem of selecting a few pixel groups from all pixels in a template image to meet that criterion was successfully formulated as a combinatorial optimization problem, and only images with maximized isolation from similar surrounding images were successfully extracted. According to the results of tests with various images, even if only about 1% of all images are used, recognition rate in the range of 96%–99% was accomplished by this image matching.
This method will show its power in fields like detection of various objects on production lines (which is a task that requires both excellent discrimination ability and high speed).
Feature-value matching that reflects uneven shapes of objects by using a multi-flash camera
By using information that captures shapes like slight undulations on objects, object detection applicable to objects with no patterns (which has hitherto been difficult) was accomplished.
In this study, a multi-flash camera (with multiple LEDs arranged around the periphery of the camera) was used, and plural images (each taken on each flash of an LED one by one) were used. The group of images taken reflects the shading of the unevenness of the object in relation to the lighting direction, and a single feature-value image (which accumulates information concerning the uneven shape) is generated. By using the feature-value image for matching, high-reliability detection is possible even in the case of objects little patterning.
This matching method can be applied for object recognition of intermediate workpieces being treated in factories.
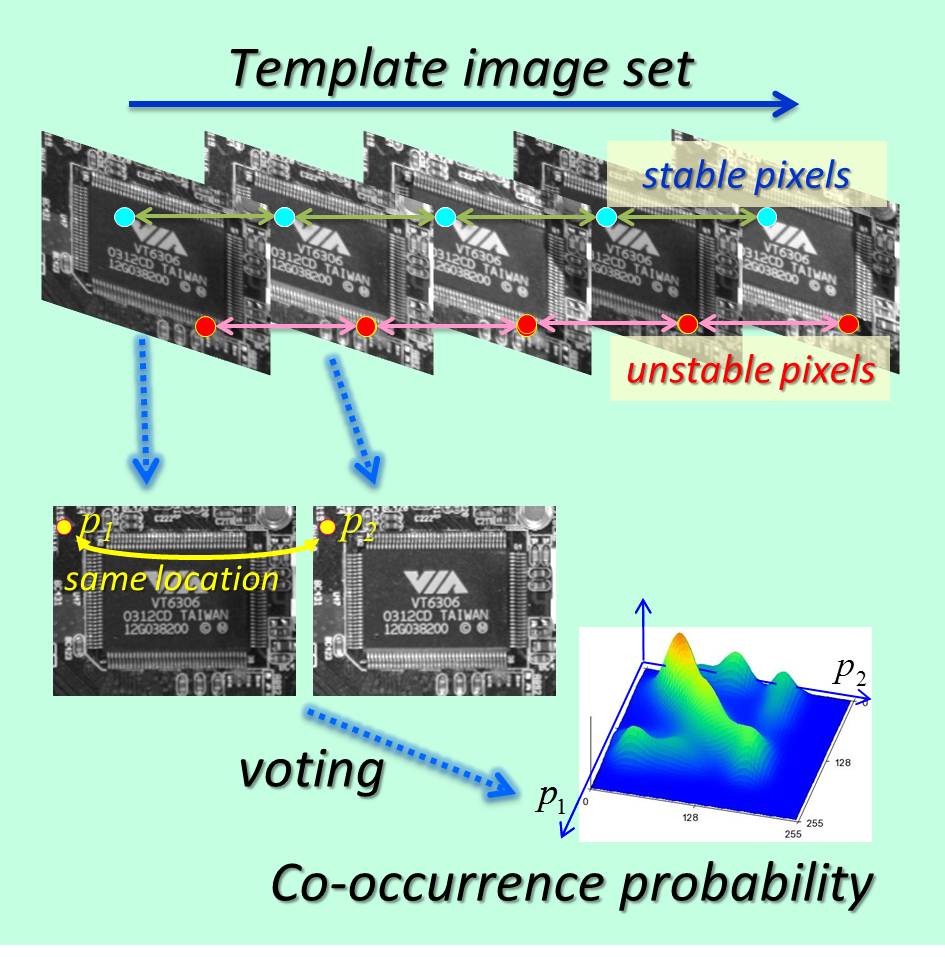
Object detection robust against variation in lighting based on probability assessment of brightness stability
In the case that plural template images are used, it is possible to dramatically improve robustness against lighting variation by evaluating brightness stability between images.
In this study, a template-image group containing four or five images aligned in advance is used. Such groups are combined in pairs, and brightness-co-occurrence probability distributions between images are expressed as 2D histograms. The stability of images is then assessed by using these histograms. By applying this matching method in combination with conventional CPTM as an improved type of template matching, it is possible to extract images with temporal stability and spatial uniqueness in a balanced manner. Even in the case of strong illumination noise (as when the sun is setting), recognition rate of 97.6% was achieved.
This template-matching method will show its power in practical on-site applications such as those in which lighting conditions vary or are difficult to control (such as production lines).

 The main research areas of the ISL are;
The main research areas of the ISL are;