Last updated: Feb. 27, 2019.

ロボットの知能化を目的として,3次元センシング,
ヒューマンセンシング,画像センシングの3分野で
研究プロジェクトが進められています.
■3次元物体形状を考慮した日用品の機能認識
■プリミティブ物体近似によるロボットの動作パラメータ決定
■3次元ベクトルペアを用いたビンピッキング視覚
■3D-CGを用いた特徴点選択によるばら積み物体の認識
■3次元点群の粗さに依存しない物体認識
■CCDoN特徴量を用いた高速・高信頼物体認識
■輪郭の構造分析に基づくアピアランスベース物体認識
■ハンドアイロボットのための物体認識戦略の自動算出
■平面部にも強い3次元特徴量ベース物体認識
■点群密度の変化と欠落に頑健な局所参照座標系(DPN-LRF)の提案
■3D物体認識のための高速キーポイント検出および特徴量記述
■組立作業における作業者の視線と手の動きに着目した習熟プロセスの分析
■存在確率の遷移分析に基づく組み立て作業の記述
■顔キーポイントの移動方向コードに基づく個人依存しにくい表情識別
■中長期の連続画像モニタリングによる顔表情変化の検出
■3次元モデルの形状と人の印象のマッピング
■非定常動作検出のための定常動作識別の高信頼化とトイレ空間への応用
■アンビエントセンシングに基づくロボット安全システム
■マーカレスピアノ演奏スキル評価システム
■3-Dハンドモデルを用いたオンライン画像生成に基づく仮説検証型ピアノ運指認識
■濃度共起確率に基づく超高速テンプレートマッチング(CPTM)
■CNN中間層を利用した画素選択型テンプレートマッチング
■周辺類似物体との分離性を最大化する画像マッチング
■マルチクラス識別機能を有するテンプレートマッチング
■統計的外乱画素推定に基づく遮蔽に頑健な画像照合
■マルチフラッシュカメラを用いた物体の凹凸形状を反映した特徴量マッチング
■類似度分布の連続性に基づく高速サブピクセルマッチング
■濃度安定性の確率的評価に基づく照明変動に頑健な物体検出
■複数の移動パターンに対する同時多点追跡手法
■サブトラッカの最適配置に基づくオクルージョンに強い物体追跡
■SIFTキーポイントの効率的な削減アルゴリズム
企業殿との共同研究を積極的に展開しています.
これに関するお問い合わせは,橋本までお願いいたします.
email: mana@isl.sist.chukyo-u.ac.jp
3次元センシング – 3-D Sensing
3次元物体形状を考慮した日用品の機能認識
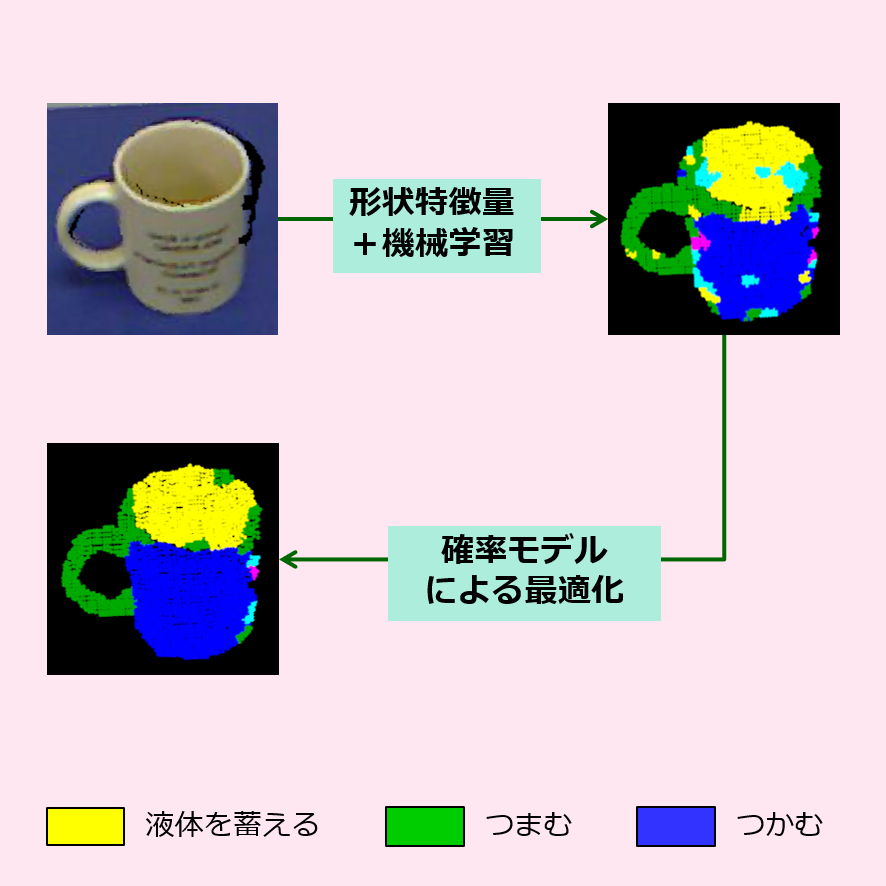
コップに備わる”液体を蓄える”という機能に代表されるような,日用品に備わる機能を認識する手法を提案しました.
”液体を蓄える”という機能はくぼみ形状から作られるように,日用品の機能は物体形状と強く関係すると考えられます.このことに着目し,提案手法では,まず局所的な形状を表す特徴量と機械学習を用いることによって,対象物の機能を認識します.次に,大域的な形状情報を再評価するために設計した確率モデルを,さきほどの認識結果に導入します.このような2段階評価を用いることにより,認識率77.0%で機能を認識できるようになりました.
本技術は,生活支援ロボットのほか,生産システムにおける類似形状部品の認識や,工具認識のためのビジョンシステムに応用可能です.
プリミティブ物体近似によるロボットの動作パラメータ決定

複数の物体が存在するシーンにおいても,対象物をプリミティブ物体近似し,ロボットの動作パラメータを決定する手法を開発しました.
本研究では,対象物を構成する面情報に着目し,仮説検証を用いてシーン中に存在する面領域を組み合わせることにより,対象物をプリミティブ形状で近似します.そして,近似結果と把持ルールを用いて,ロボットの動作パラメータ(アプローチ位置,方向,角度,開口幅)を決定します.仮説検証を用いて最適な対象物の領域を認識するため,前処理にセマンティックセグメンテーション(対象物の領域抽出)を必要としない手法を実現しました.
本技術は,物流ロボットや生産システムで使用されるビジョンシステムに応用できます.
3次元ベクトルペアを用いたビンピッキング視覚
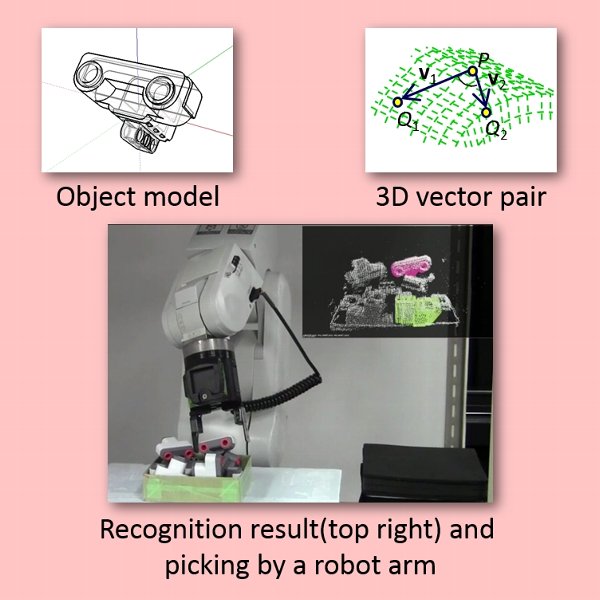
ばら積みされた物体の位置姿勢を認識するビンピッキング視覚を開発しました.対象物体の形状を事前分析し,特徴的な局所形状部分をモデルデータとして登録することにより,効率よく物体を検出することが可能です.
本研究では,始点を共有する2本の3次元空間ベクトル(ベクトルペア)をマッチングの単位として設定し,対象物体の中で特徴的なベクトルペアを抽出します.複数のベクトルペアを入力距離データと照合し,多くのベクトルペアに支持された位置姿勢を出力します.データ量がきわめて少ないので高速であり,また特徴的なデータのみを使用するので誤認識の危険性が低いという利点があります.実験により認識成功率93.1%,処理時間1.36秒を実証しました.
組み立て作業などに用いられるロボットの3次元視覚システムや
物体モデリングなどの分野に適用可能です.
3D-CGを用いた特徴点選択によるばら積み物体の認識
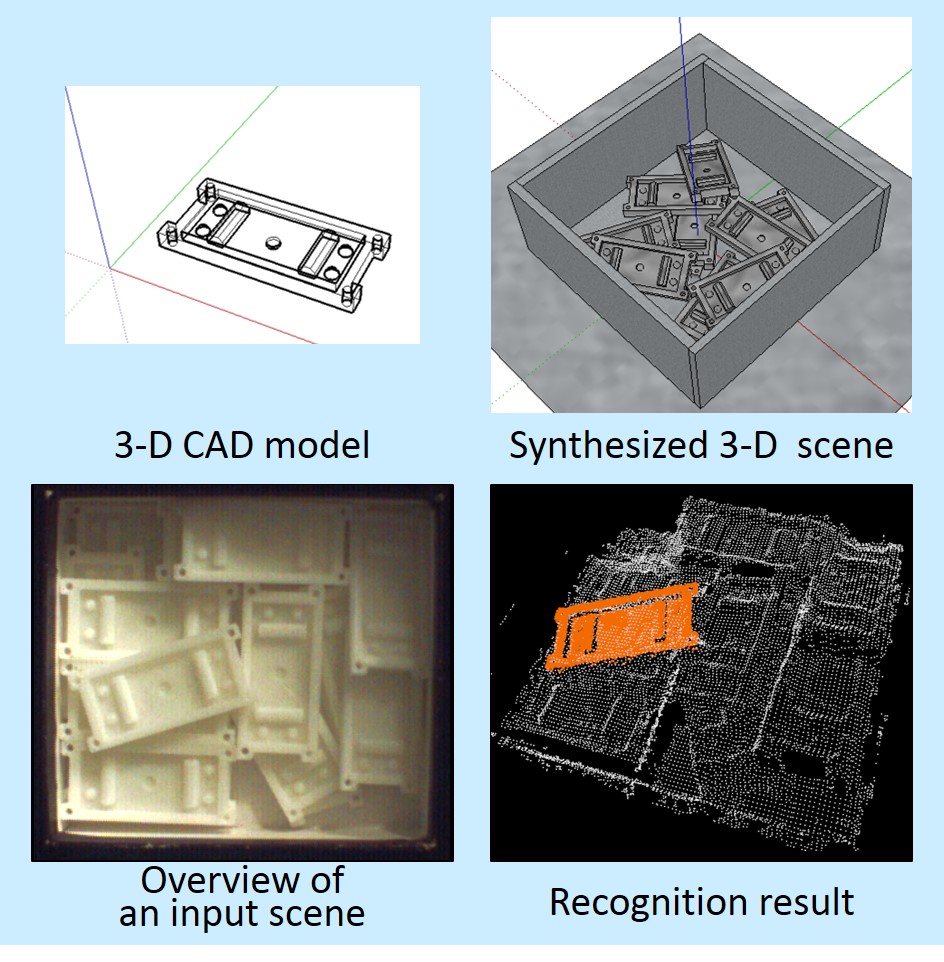
ばら積みシーンにおいても,物体を高信頼に認識できるロボット視覚を開発しました.物体モデルから選択した識別性能が高い特徴量のみを用いることによって信頼性の高い照合が可能です.
物理シミュレータと3D Computer Graphics(3D-CG)の技術を利用して入力データを予測し,入力データに発生しうる特徴量を生成します.そして,この特徴量群を用いて物体モデルから特徴空間において識別性能が高い特徴量を持つ3次元点を特徴点として選択し,認識に使用します.提案手法では,高速化の観点からベクトルペアを使用し,識別性能が高い少数のベクトルペアを認識に用いることによって,高信頼かつ高速な認識を実現しました.
産業用ロボットのビジョンシステムをはじめ,物体同士が接触した複雑なシーンの物体認識などに適用可能です.
3次元点群の粗さに依存しない物体認識
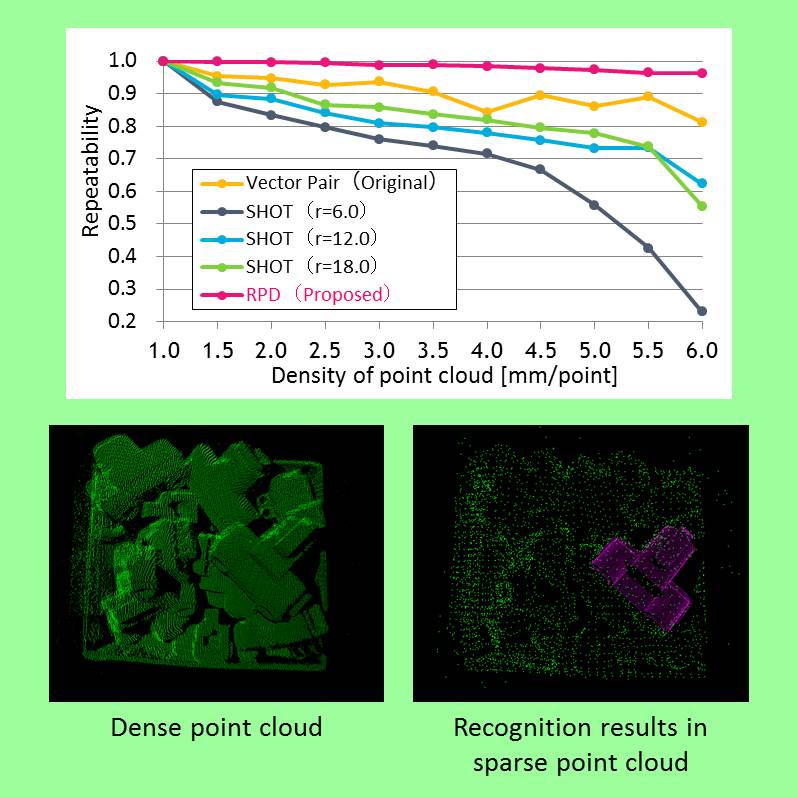
物体モデルと入力シーンの点群の粗さが大きく異なる場合でも,物体を高信頼に認識できる手法を開発しました.
本研究では,局所領域の相対的な点数比が点群の粗さに対する不変量であることに着目し,これを記述したRelative Point Density(RPD)特徴量を新たに提案し,マッチングに使用します.3Dセンサと対象物間の距離の変化や,センサ自身の計測方式の異なりに起因した,点群の密度の違いにロバストな認識を実現しました.
移動走行車に用いる障害物発見のためのビジョンシステムや産業用ロボットの物体認識などに適用可能できます.
CCDoN特徴量を用いた高速・高信頼物体認識

ばら積み部品の高速・高信頼認識のための新特徴量を提案しました.
本研究で提案する特徴量は異なる球領域で算出した2つの曲率値と法線ベクトル間の差分値から算出したDifference of Normals (DoN)特徴量を組み合わせた3つの形状評価値から構成されます.この特徴量をCombination of Curvatures and Difference of Normals(CCDoN)と呼びます.従来のDoN特徴量は法線ベクトル間の差分値から算出した相対値で表現されるため,同じ相対値をもつ特徴点との誤照合を起こす可能性がありました.そこで本研究では,DoN特徴量と同様にスカラー値であり,姿勢変動に頑健な曲率値を組み合わせることによって,特徴量の信頼性を高め,誤照合の低減を図ります.CCDoN特徴量の各値は,特徴点周りの局所形状,
大域形状,法線間の差分値を表現しています.3つの異なる値を照合に
利用するため,従来のDoN特徴量よりも誤照合の低減ができ,高速
かつ高信頼な照合が可能です.
ロボットビジョンシステムや自動組み立てシステムに適用可能です.
輪郭の構造分析に基づくアピアランスベース物体認識
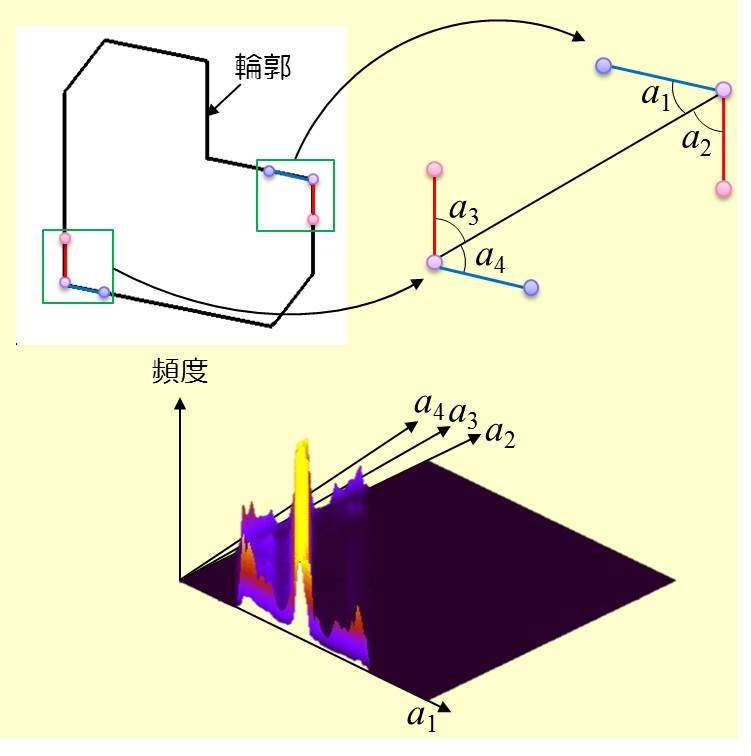
対象物体の輪郭の局所的な接続構造を分析し,物体形状を特徴づけている独自性の高い線素対を抽出して照合に用いる物体認識手法を提案しました.
本研究では,外輪郭点列を短い線素群に分割して,結合した各線素対の対象物体全体における発生確率を計算し,発生確率が低い線素対のみを選択して照合に用います.このような線素対を単位とする照合によって,学習データを3次元形状モデルから自動生成できるだけでなく,効率的な照合が可能です.実画像による実験の結果,認識成功率94.2%を達成しました.
本手法は,自動組立ロボットやホームロボットなど,実環境でのロボットビジョンに適用可能です.
ハンドアイロボットのための物体認識戦略の自動算出

産業用ロボットアームの手先に配置された小型の汎用カメラと簡易的なレーザ計測システムを用いて,対象物の位置と姿勢を自律的に認識するシステムを開発しました.
センサシステムは,対象物の形状を精密に計測する小型カメラと,レーザポインタによる1点の3次元測距装置から構成されるハンドアイシステムです.提案システムは,カメラによる対象物の外形認識結果をもとに,測距すべき箇所と個数などの物体認識戦略を自動的に決定し,ロボット操作にによって自動的に3次元姿勢計測を行います.目的によって精度優先型または計測時間優先型の戦略を選ぶこともできます.クリアランス1mmの円孔に円柱を挿入する実験に成功しました.
この成果を,ロボットアームによる自動組立システム等に適用開発中です.
平面部にも強い3次元特徴量ベース物体認識

物体表面が平面的であっても安定して認識できる3次元物体認識手法を開発しました.
3次元特徴量を用いた物体認識が普及していますが,物体の見えが平面的である場合にはキーポイント上の特徴量が安定せず,認識率が低下するという問題がありました.これは,平面では形状に特徴が少ないことから参照座標系が不安定になることに起因しています.そこで本研究では,平面的な表面に対しても有効な参照座標系GRF(Global Reference Fram)を新開発し,従来の非平面に強いベクトルペアマッチング法(VPM)と適応的に組み合わせることによって,見えの平面性に依存しない物体認識を実現しました.
現実の生産ラインでは,平面を多用した工業製品が多いため,本技術により品種に依存しない安定的な物体認識が期待できます.
点群密度の変化と欠落に頑健な局所参照座標系(DPN-LRF)の提案
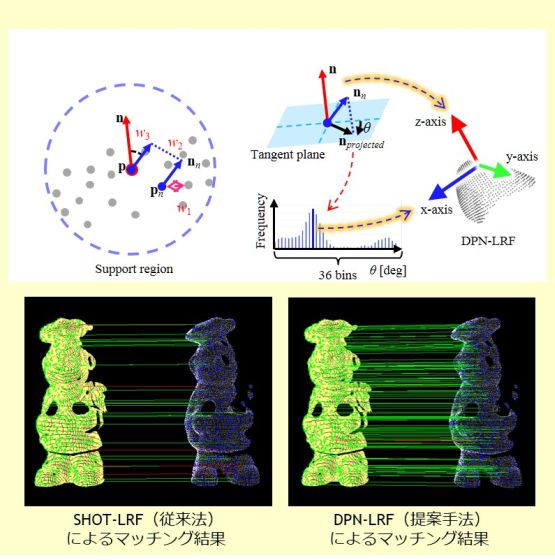
点群の密度変化や欠落が生じていても高信頼にマッチングを実現するための局所参照座標系DPN(Dominant Projected Normal)-LRFを開発しました.
局所参照座標系LRF(Local Reference Frame) は,キーポイントごとに設定される局所的な参照座標系です.これまで,照合対象の点群に密度の違いや欠落が発生していた場合にはLRFが不安定となり,キーポイントマッチングに失敗するという課題が残されていました.本研究では,これらの外乱に対して頑健なLRFの計算方法を提案しました.従来のLRFを,DPN-LRFに差し替えるだけで,マッチングの信頼性が向上することを確認しました.
ホームロボット等,移動ロボットのための物体認識システムに適用可能です.
3D物体認識のための高速キーポイント検出および特徴量記述
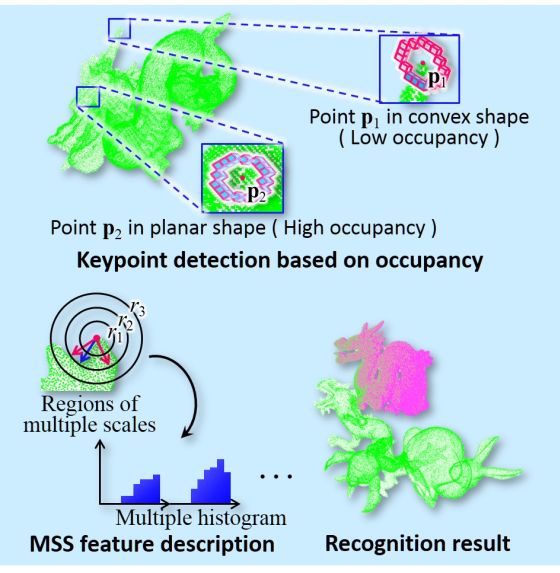
3次元物体認識のための高速なキーポイント(特徴点)検出および特徴量記述手法を開発しました.
本手法は,局所領域に対する計測点群の割合(占有率)に基づくキーポイント検出と,マルチスケールの球の最外殻のみを記述領域としたMulti-Scale Shell(MSS)特徴量記述によって構成されます.占有率の算出は局所領域内の点数を計測するシンプルな処理と同等であり,さらにMSS特徴量は限定された記述領域内の点群のみを用いて記述されるため,高速性に優れています.3次元物体認識の性能を従来手法と比較した結果,認識率は同等でありながら,処理速度は約3倍高速であることを確認しました.
移動走行車や産業用ロボットのためのビジョンシステムをはじめ,モデル検索などにも適用可能です.
ヒューマンセンシング – Human Sensing
組立作業における作業者の視線と手の動きに着目した習熟プロセスの分析
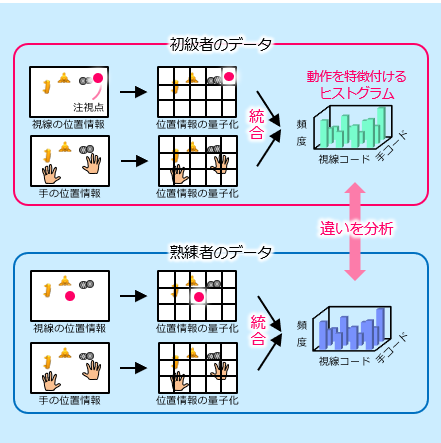
組立作業の作業者の視線と手の動きに着目し,作業者が初級者から熟練者へ成長する過程を分析する手法を開発しました.
提案手法は,2次元で表現される視線と手の位置情報を18個の領域に量子化し,18種類のコードで表現します.そして,同時刻における視線と利き手,視線と非利き手のコードのペアの発生頻度を全フレームにわたって求め,共起ヒストグラムを生成します.これを習熟プロセス分析のための特徴量とすることによって,視線と手の連動性を分析することができます.提案特徴量を用いた分析の結果,初級者と中級者の間では,非利き手の動きが異なり,中級者と熟練者の間では,視線の動きが異なることが分かってきました.
本技術は,製造現場における作業者の教育・訓練システムや,熟練作業ロボットに応用できます.
存在確率の遷移分析に基づく組み立て作業の記述
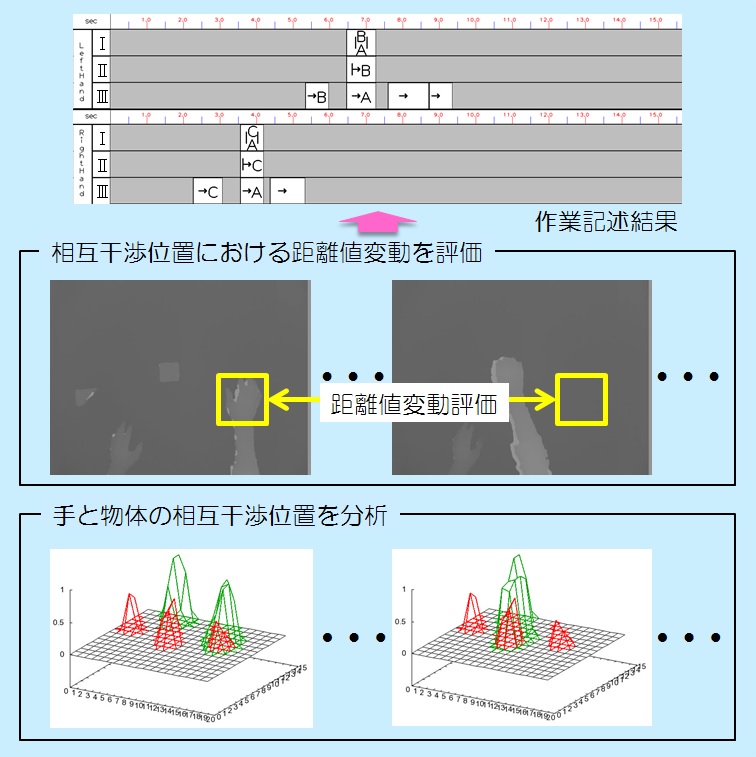
組み立て作業を分析するための記述フォーマットを提案し,それに従った自動記述を実現するセンシングシステムを開発しました.
記述フォーマットには,左右の手による手の移動,物体を移動させる動作,物体同士を結合させる動作が記述されるように設計されています.提案したセンシングシステムは,手と物体の存在位置を確率的に表現したデータを用いることによって,手と物体が相互に干渉する位置を特定し,手の移動を記述できます.さらに,手と物体の相互干渉位置において,センサから物体までの距離の変動を分析することによって,物体を移動させる動作,物体同士を結合させる動作を記述できます.その結果,作業のプロセスおよび左右の手の使用状況を確認できる機能を持たせることができました.
新人作業者と熟練作業者の記述結果を比較することによって,作業
改善への応用が期待できます.
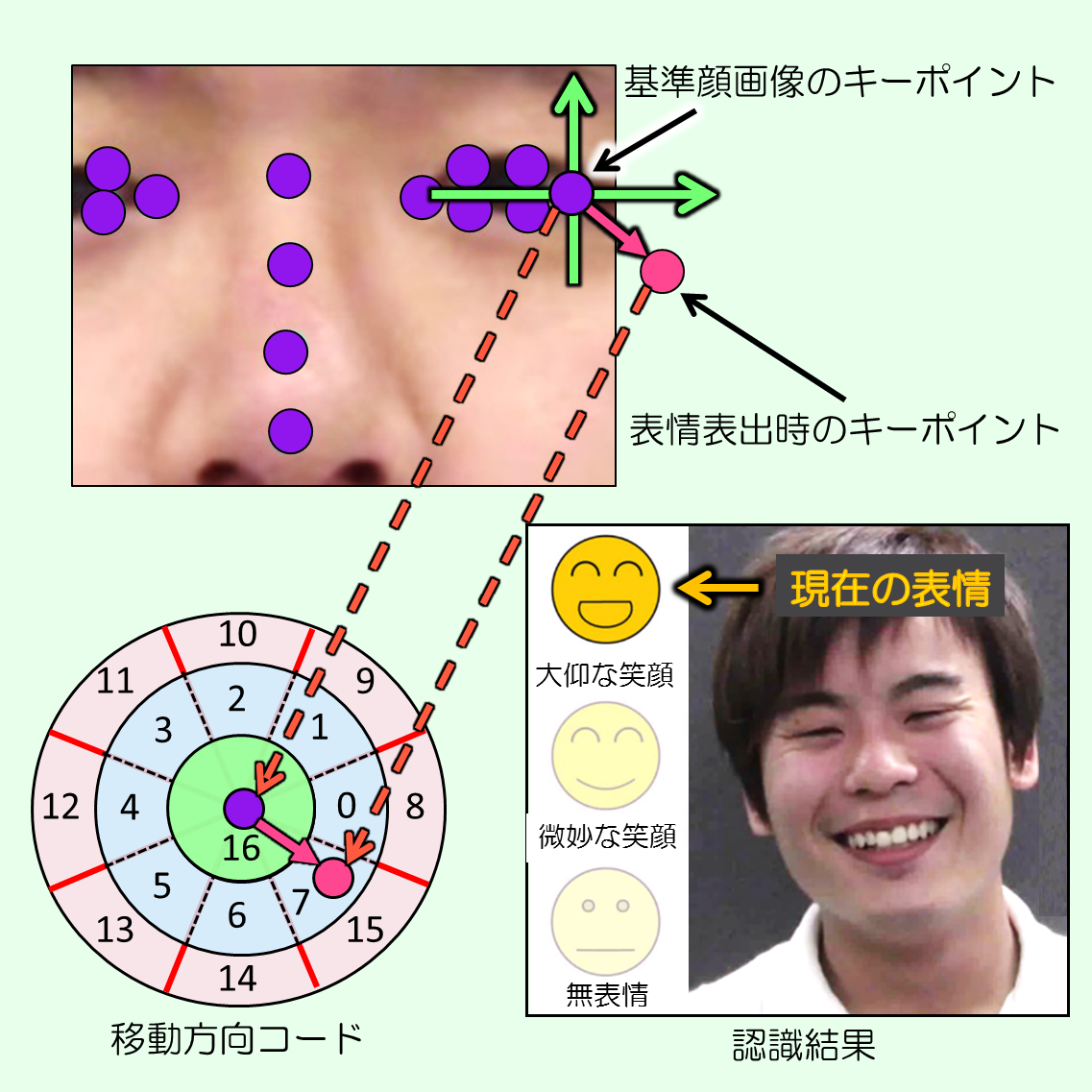
顔キーポイントの移動方向コードに基づく個人依存しにくい表情識別
 サービスの質の評価のために,ユーザの笑顔度合いを読み取る必要があります.この場合,実用性の観点から2つの課題があります.1つめの課題は,大仰な表情と微妙な表情を識別することです.2つめの課題は,未学習者の表情を識別することです.本研究では,学習者に依存しにくい大仰と微妙な喜び表情の識別手法を提案しました.
サービスの質の評価のために,ユーザの笑顔度合いを読み取る必要があります.この場合,実用性の観点から2つの課題があります.1つめの課題は,大仰な表情と微妙な表情を識別することです.2つめの課題は,未学習者の表情を識別することです.本研究では,学習者に依存しにくい大仰と微妙な喜び表情の識別手法を提案しました.
まず,顔の眉,口などの部位からキーポイントを抽出し,基準顔画像の対応するキーポイントからの移動方向と移動量を算出します.これらをそれぞれ量子化することで移動方向コードとし,特徴量とします.複数人の学習画像から生成した表情ごとの特徴量の頻度分布に基づき,表情ごとに異なり,かつ不特定多数の人に共通する特徴量を選択し,識別に用いることによって,2つの課題を解決しました.
テレビ番組の視聴率調査や人とロボットのコミュニケーションツール
など,不特定多数の人の感情をセンシングする手法として期待されます.
中長期の連続画像モニタリングによる顔表情変化の検出
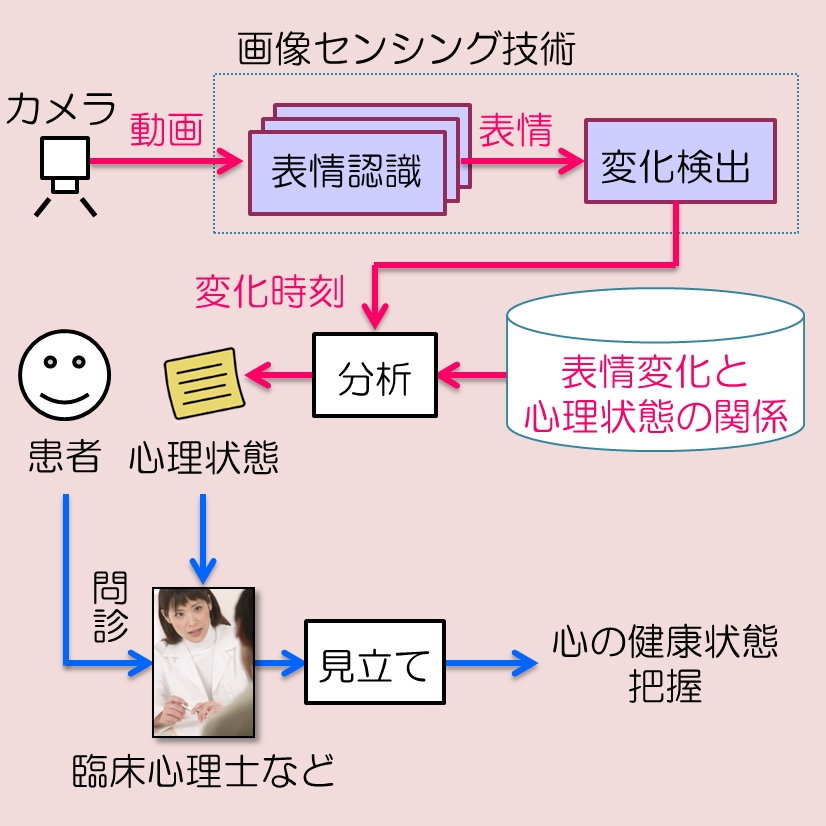
独居高齢者の心のケアや,ストレス社会で暮らす人の心の健康状態をタイムリーにモニタリングするために,顔表情の変化に気づくシステムが求められています.
本研究では,当研究室で開発した,静止画を対象としたGabor特徴を用いた微妙な顔表情認識手法を発展させ,動画像からの顔表情の変化時刻検出手法を提案します.連続顔画像の各フレーム(時刻)を,表情の大きさを基準にして3つのクラス(大仰な喜び,微妙な喜び,無表情)に分類します.これらを時系列の記号列と見なし,記号化された表情のならびから,表情変化が生じた時刻を推定します.実験の結果,適合率87.8%,再現率84.5%を確認しました.
家庭などで一定間隔で記録された顔画像列をもとにした,日々の心の健康状態の変化を把握するシステムとして,例えば専門の臨床心
理士による診断の補助的計測に適用できます.
3次元モデルの形状と人の印象のマッピング
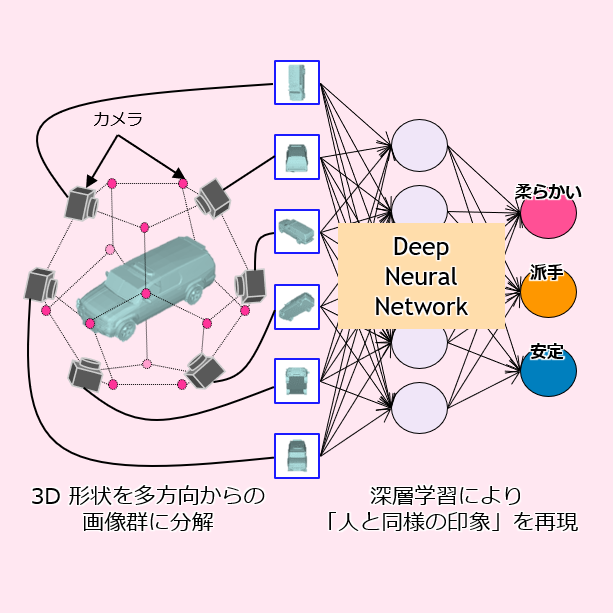
3 次元モデルの形状に対して人が感じる印象を定量的に自動で推定する手法を開発しました.
本研究では,人の 3 次元形状の知覚プロセスに基づき,複数の視点から 3 次元モデルをレンダリングした画像群を入力データとするDeep Neural Networkを用いて,人が感じた印象を推定しています.実験の結果,車,花瓶,椅子というさまざまなカテゴリのデータセットに対して,本手法の推定結果と人が評価した値の高い相関関係を確認しました.
本技術は,直感的な3次元モデルの設計・検索システムへの応用が可能です.
非定常動作検出のための定常動作識別の高信頼化とトイレ空間への応用
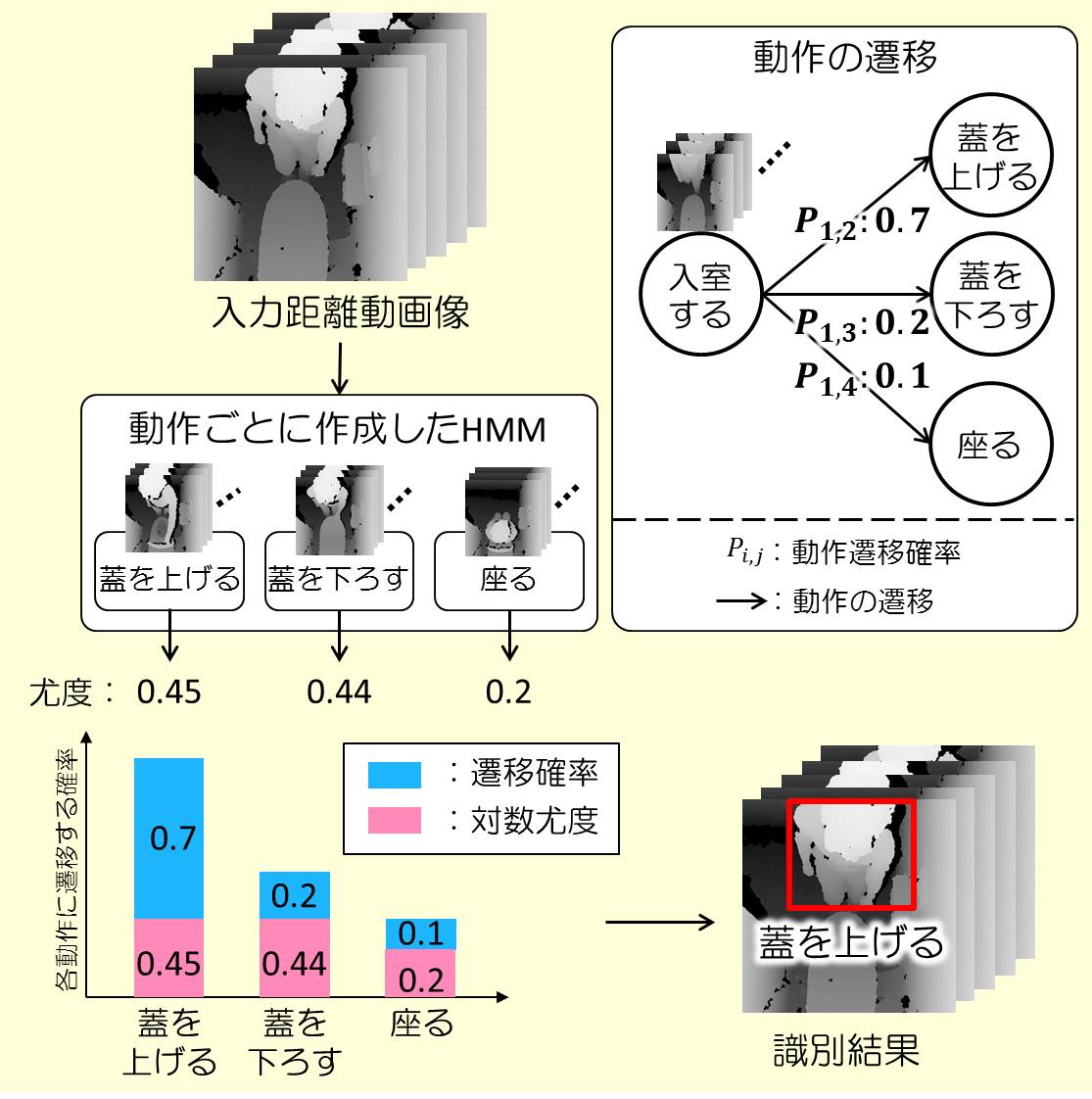
独居高齢者の増加や介護者の減少により,高齢者の事故が増加傾向にあるため,事故につながる非定常動作を自動的に検出するシステムが求められています.本研究では,非定常動作検出のための定常動作を高信頼に識別する手法を提案し,高齢者の事故が多いトイレ空間に応用しました.
人間が日常生活においておこなう動作の発生順序が,行動ごとにパターン化されていることに着目し,各動作の画像的な特徴だけでなく動作間の遷移のしやすさも考慮して動作を識別します.HMM(隠れマルコフモデル)をベースとし,各HMMから出力される尤度と,動作間の遷移のしやすさを表す確率を用いて動作を識別します.これにより,画像的な特徴が類似した動作であっても,発生順序の違いから可能性が低い遷移を抑制し,高信頼な動作の識別を実現しました.
本技術は,トイレ内の高齢者の非定常動作検出のほか,さまざまな
環境下における高齢者の単独事故防止システムへの応用が期待されます.
アンビエントセンシングに基づくロボット安全システム
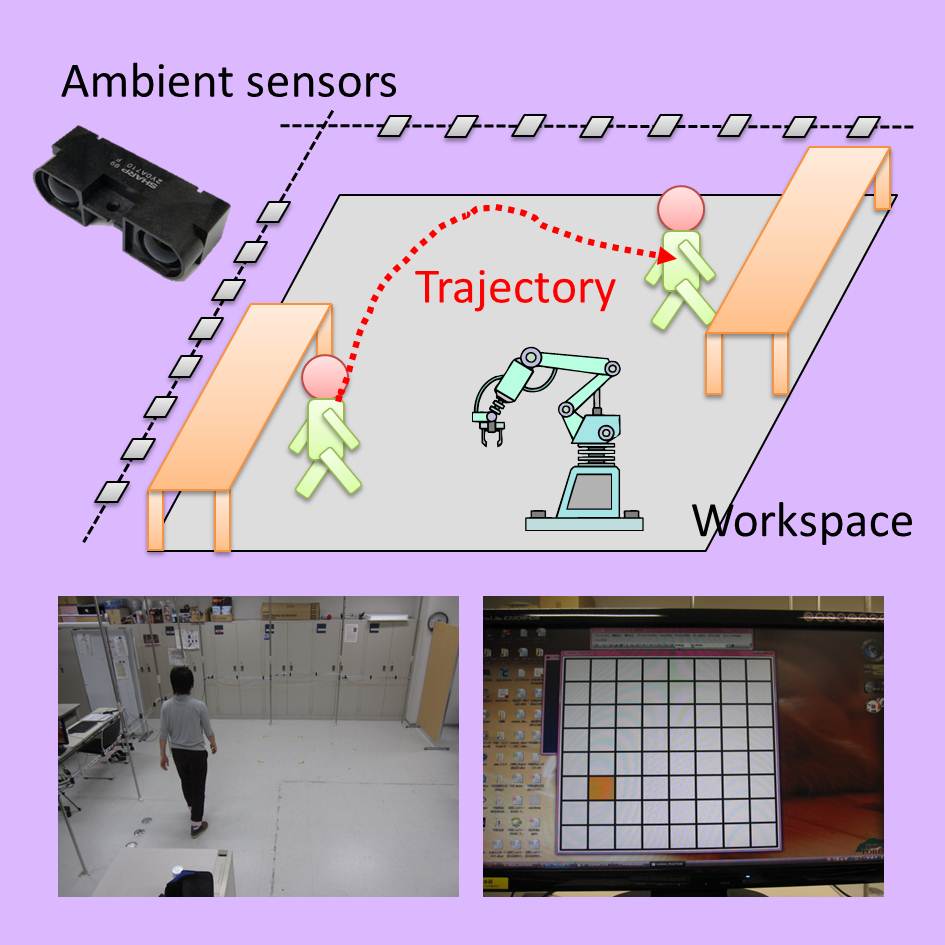
近年,ロボット安全分野が注目されており,ロボットと人間が共同作業空間における相互の接触予防が重要な課題となっています.本研究では,複数の簡易型測距センサの組み合わせによって作業空間における人間の存在確率分布を算出する技術を開発しました.
1次元的な測距が可能な赤外センサを室内に配置し(Ambient sensors),その組み合わせ信号と人間の位置座標の対応を学習させます.これをANNを用いて識別することによって,未知の信号列から人間の位置を推定します.このとき,信号列と位置座標の関係をベイズ推定の枠組みで補間することによって,突発的な計測エラーを抑制しました.実験によって認識成功率 83.6%,処理時間 0.18 ミリ秒を確認しました.提案手法はKinect等のエリアセンサ方式より応答性の点で優れており,ロボット安全のようなリアルタイム処理に適しています.
マーカレスピアノ演奏スキル評価システム
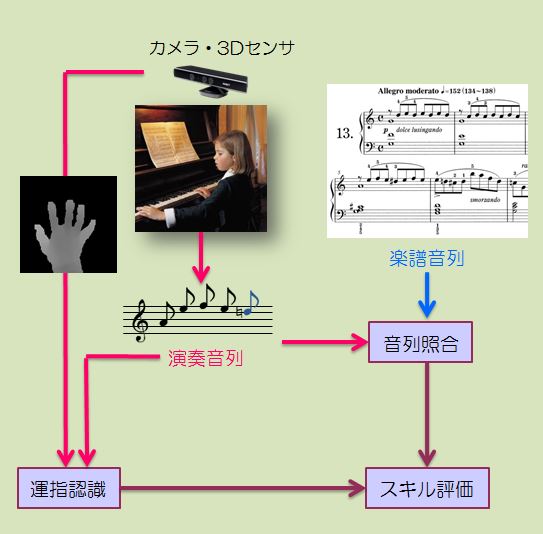
初心者のピアノ演奏スキルの向上においては,正しい音を正しい指使いで弾くことが重要とされており,演奏音列と電子楽譜を用いた音列照合と,打鍵した指を同定する運指認識の2つの技術要素が必要です.
音列照合は,演奏音列データと電子楽譜を柔軟にマッチングさせます. 運指認識は,レンジセンサで撮影した距離動画像を分析し,膨大な学習データと効率的に照合することによって,運指状態を判断します.マーカを一切使わないことが特徴です.本研究では,これらの技術をそれぞれ開発して統合し,ピアノ演奏スキル評価システムを実現しました.
本システムにより,ピアノレッスン品質が向上するとともに,ピアノ演奏を題材としたスキル獲得プロセスの定量分析手段としても利
用できます.このほか,熟練作業者による高度ものづくり技術の分
析や,医療の観点からの高齢者の手指運動機能の解析など,さまざ
まな分野への応用も期待されます.
3-Dハンドモデルを用いたオンライン画像生成に基づく仮説検証型ピアノ運指認識
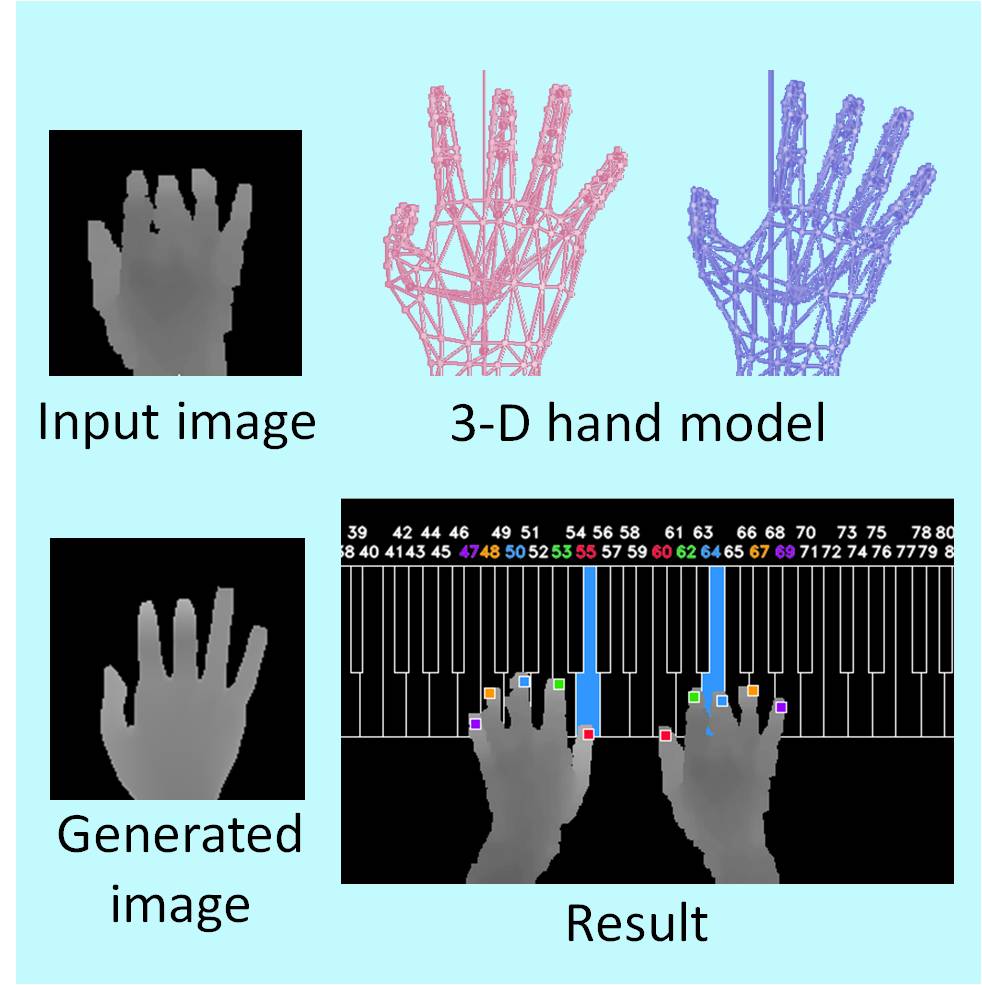
マーカレスに加えて,演奏者によらず使用でき,事前の学習が不要なピアノ演奏の運指を観測する手法を開発しました.
本研究では,仮説検証型アプローチをとります.手指の距離画像から指先位置候補を多数検出し,ピアノキーとの対応を[確率的に表現]したものを仮説群として生成します.各仮説から手全体の3次元形状を推定し,汎用3-Dハンドモデルを用いてオンラインで画像化します.それらを実際の入力画像と比較照合することによって最尤仮説を決定し,運指状態を判断します.また仮説生成段階では,各仮説の手の自然さを評価し,事前に仮説を削減することによって処理の効率化を図っています.
本技術は,初心者向けのピアノ演奏スキル評価システムのほか,手指の動作によって直接的に操作するユーザーインターフェイスや手
話の認識など,さまざまな手指の動作解析への応用が期待されます.
画像センシング – Image Processing
濃度共起確率に基づく超高速テンプレートマッチング(CPTM)
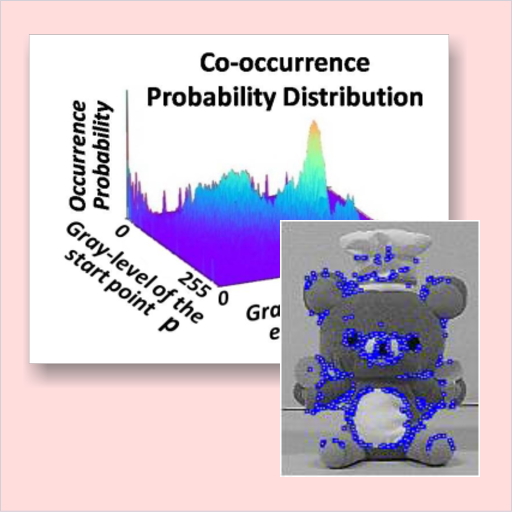
テンプレートマッチングは,画像から目的の物体を検出する汎用的な技術です.本研究では,テンプレート画像に含まれる全画素のなかから,ユニークな画素だけを自動的に選び出すことによって,きわめて少数のデータだけを用いる超高速なマッチングを実現しました.
複数の画素からなる画素パターンの共起発生確率を計算し,確率値が小さいパターンほどユニークであると考えます.この技術により,テンプレート画像中のわずか 0.6% の画素だけを使って従来の約170倍の高速処理が実現し,しかもほぼ 100% の認識率を達成できることが確認されました.
生産ラインにおける部品検査,組立ロボットのほか,対象物や人物の高速な追跡など,幅広い用途に利用できます.
CNN中間層を利用した画素選択型テンプレートマッチング
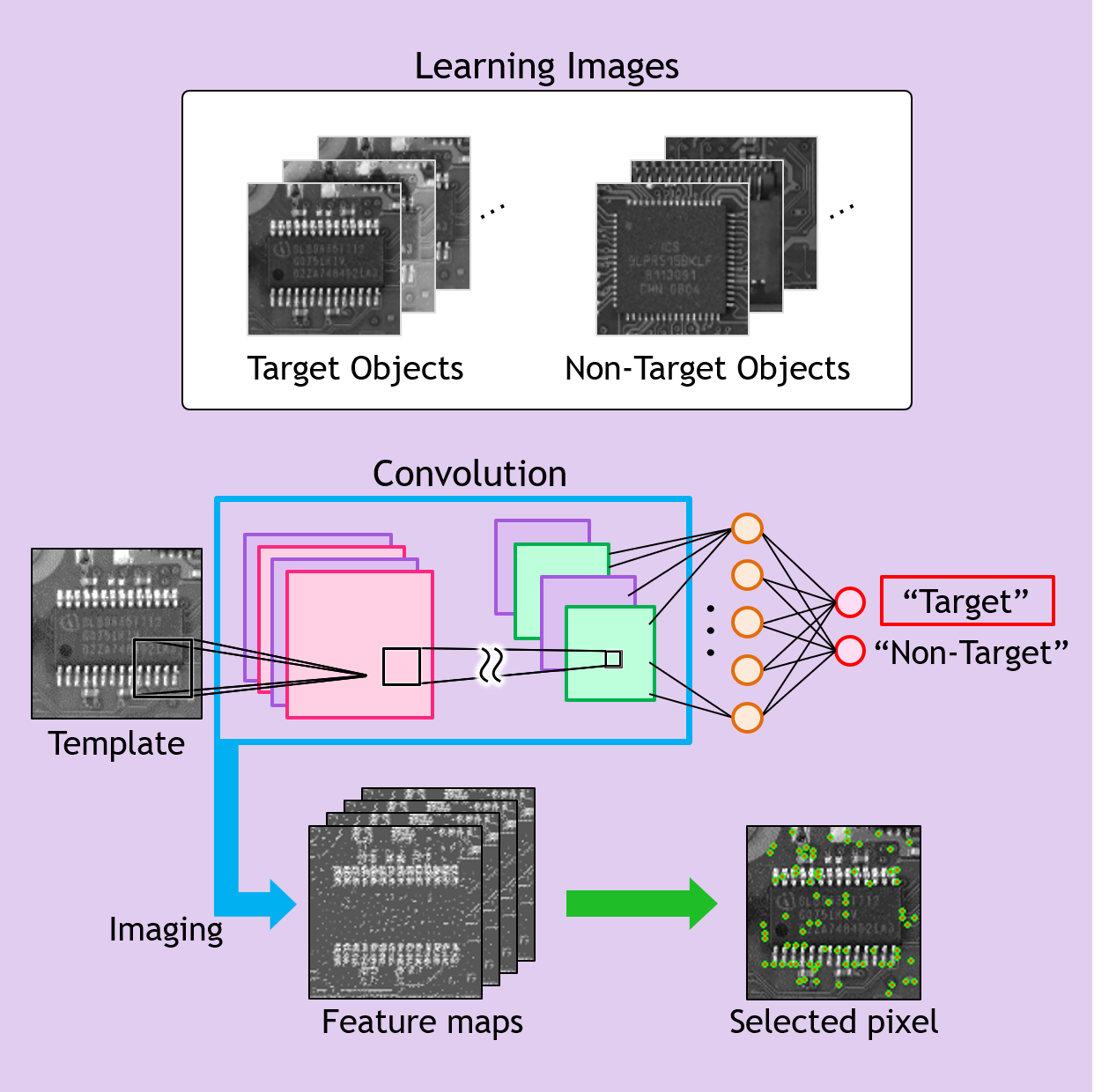
画素選択型マッチングに関して,CNNの中間層を利用して画素を選択する研究にも取り組んでいます.
検出したい物体をクラス“対象物(テンプレート)”とし,それ以外の物体を全てクラス“非対象物”として学習したCNNを利用します.CNNの中間層で生成される特徴マップでは識別に有効な情報が抽出されていること,また,特徴マップはネットワークに入力された画像との位置の対応関係があることに注目します.テンプレート画像をCNNへ入力したときの特徴マップから,応答値が高い位置を参照することによって,CNNの識別に寄与している情報に基づいた画素選択が可能となります.このようにして選択した画素は識別能力が高く,実験の結果,従来の画素選択型マッチング法よりも高い精度でマッチングできることを確認しました.
識別性能と高速性の両立が必要な生産ラインなどの現場で利用できます.
周辺類似物体との分離性を最大化する画像マッチング

CPTMをルーツとする画素選択型マッチングの発展として,似た形状を持つ外乱物体にも惑わされないテンプレートマッチングにも取り組んでいます.検出したい対象物体(ポジティブサンプル)と,形状が似ている類似物体(ネガティブサンプル)を多数準備しておくことによって,ポジティブサンプルには共通的に含まれるがネガティブサンプルにはほとんど見られない画素を取り出すことができます.
本研究では,テンプレート画像のすべての画素からこの基準を満たすごく少数の画素群を選択する問題を,組み合わせ最適化問題として定式化し,周辺類似物体との分離性を最大化する画素だけを抽出することに成功しました.さまざまな画像による実験の結果,全体の1%程度の少数の画素のみを使用しても,96% ~ 99% の認識成功率を実証しました.
識別性能と高速性の両立が必要な生産ラインでの各種物体検出など
の分野で威力を発揮します.
マルチクラス識別機能を有するテンプレートマッチング
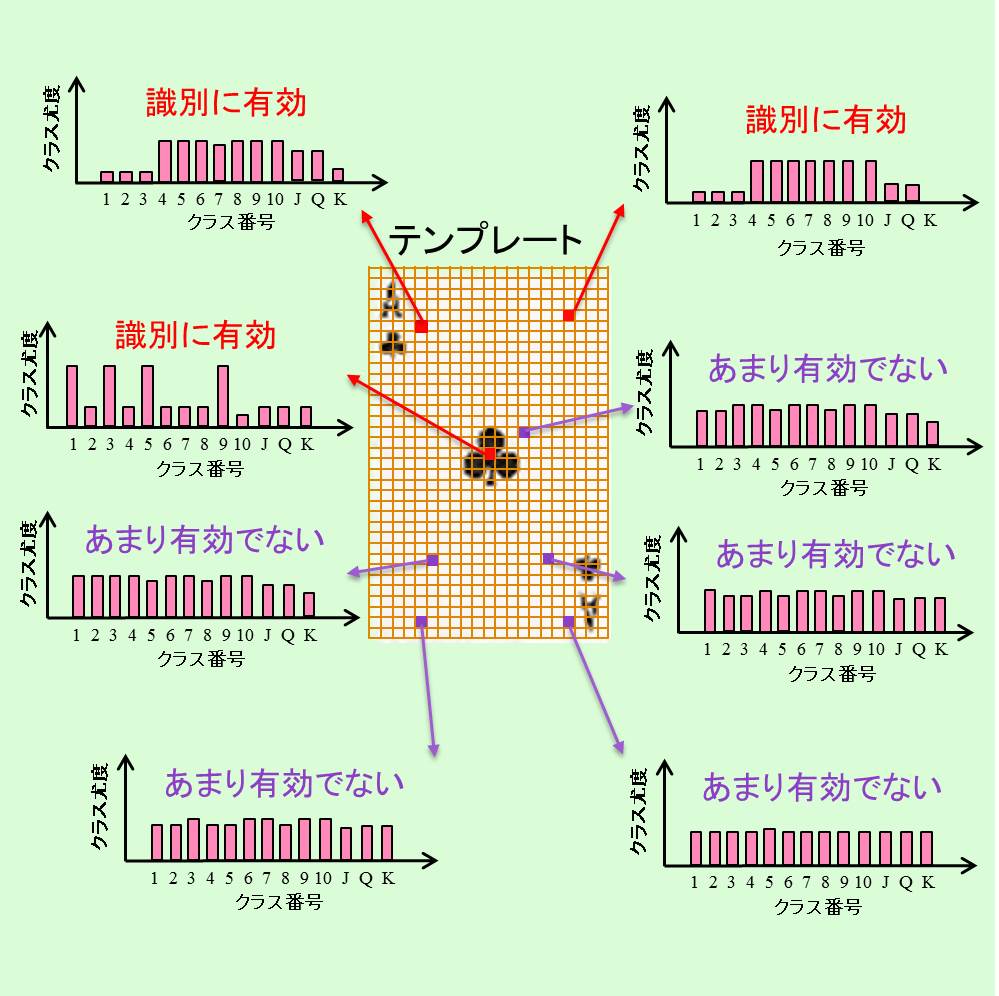
テンプレートマッチングの枠組みで複数種類の物体の位置検出とマルチクラス識別を実現する手法を提案しました.
従来のテンプレートマッチング法では,1回の処理で1つの対象物に対する類似度しか算出できず,検出する物体数に比例して処理時間が増加していました.そこで,本研究では1回の処理で複数の対象物に対する類似度を算出し,処理の高速化を図ります.テンプレート画像の一つ一つの画素にはクラス識別の能力があることに着目し,各クラスにカテゴリ分けされた多数の対象物画像を使用して各画素が持つクラス識別能力をクラス尤度ヒストグラムという形で指標化します.このヒストグラムをマッチングで使用することによって,一回の類似度計算で複数クラスの尤度を推測することができ,高速にマルチクラス識別が可能となります.
複数種類の物体を同時に検出・認識することが必要な生産ラインな
どの現場で利用できます.
統計的外乱画素推定に基づく遮蔽に頑健な画像照合
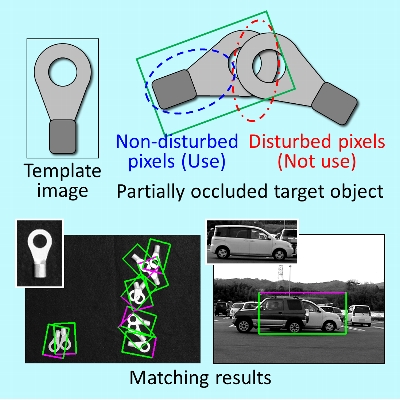
部品同士が重なる場合など対象物が部分的に遮蔽されている場合にも正確に対象物を認識する新技術を開発しました.
過去の統計的な変動傾向に基づいて遮蔽の発生している外乱画素を照合時に推定し,非遮蔽領域のみを用いて対象物を認識することで遮蔽に頑健な画像照合を実現しました.事前分析ではなく,照合時に外乱を推定することにより,遮蔽のような予測不能な突発的外乱に対するロバスト化を実現しました.実験により,約70%までの遮蔽に対して頑健な照合が可能であることを確認しました.
部品同士の重なりによる遮蔽が発生する生産ラインなどに適しています.
マルチフラッシュカメラを用いた物体の凹凸形状を反映した特徴量マッチング

物体のわずかな起伏などの形状を捉えた情報を用いることによって,これまで困難とされてきた模様のない物体にも適用できる物体検出を実現しました.
本研究では,カメラの周囲に複数のLEDを円環状に配置したマルチフラッシュカメラを用いて,LEDを1つずつ点灯させて得た複数枚の画像を使用します.この画像群は,照明方向ごとに対応する物体の凹凸の陰影を反映しており,その凹凸形状に関する情報を集約した1枚の特徴量画像を生成します.この特徴量画像を照合に用いることによって,模様が少ない物体であっても高信頼に検出することができます.
類似度分布の連続性に基づく高速サブピクセルマッチング
![]()
画素削減型テンプレートマッチングにおいて,対象物の高精度な位置計測技術を開発しました.
本研究では,CPTM画素削減技術をベースとして,サブピクセル推定に有効な参照画素を選択します.サブピクセル推定に有効な画素を類似度分布の連続性に基づいてテンプレート画像中から選択することにより,高精度なマッチングを実現します.さらに,マッチングに使用する参照画素を厳選することにより,高速なサブピクセルマッチングが可能です.実験の結果,0.05 pixel(1/20 pixel)精度でマッチングが可能であることを確認しました.
精密な部品の位置計測が必要な生産ラインなどの現場に適用可能です.
濃度安定性の確率的評価に基づく照明変動に頑健な物体検出
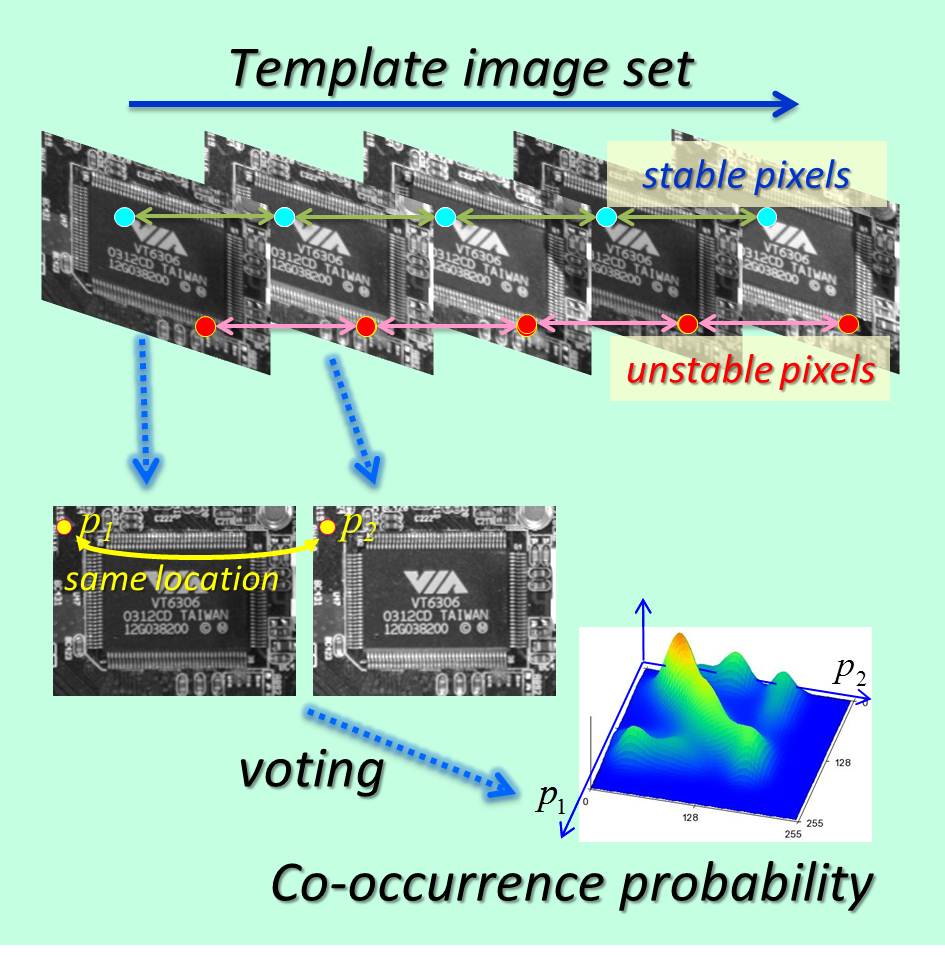
複数のテンプレート画像を利用できる場合には,画像間の濃度安定性を評価することによって照明変動に対する頑健性を飛躍的に高めることができます.
本研究では,あらかじめ位置合わせされた4~5枚のテンプレート画像群を使用します.これらを2枚ずつ組み合わせて画像間の濃度共起確率分布を2次元ヒストグラムで表現し,これを用いて画素の安定性を判断します.これを従来のCPTM法と組み合わせて更新型テンプレートマッチングに適用することによって,時間的に安定かつ空間的に独自性の高い画素をバランスよく抽出することができます.西日などの強い照明外乱に対しても 97.6% 以上の認識成功率を達成しました.
照明条件が変動しがち,あるいはコントロールが難しい生産ライン
など,実利用の現場で威力を発揮します.
複数の移動パターンに対する同時多点追跡手法
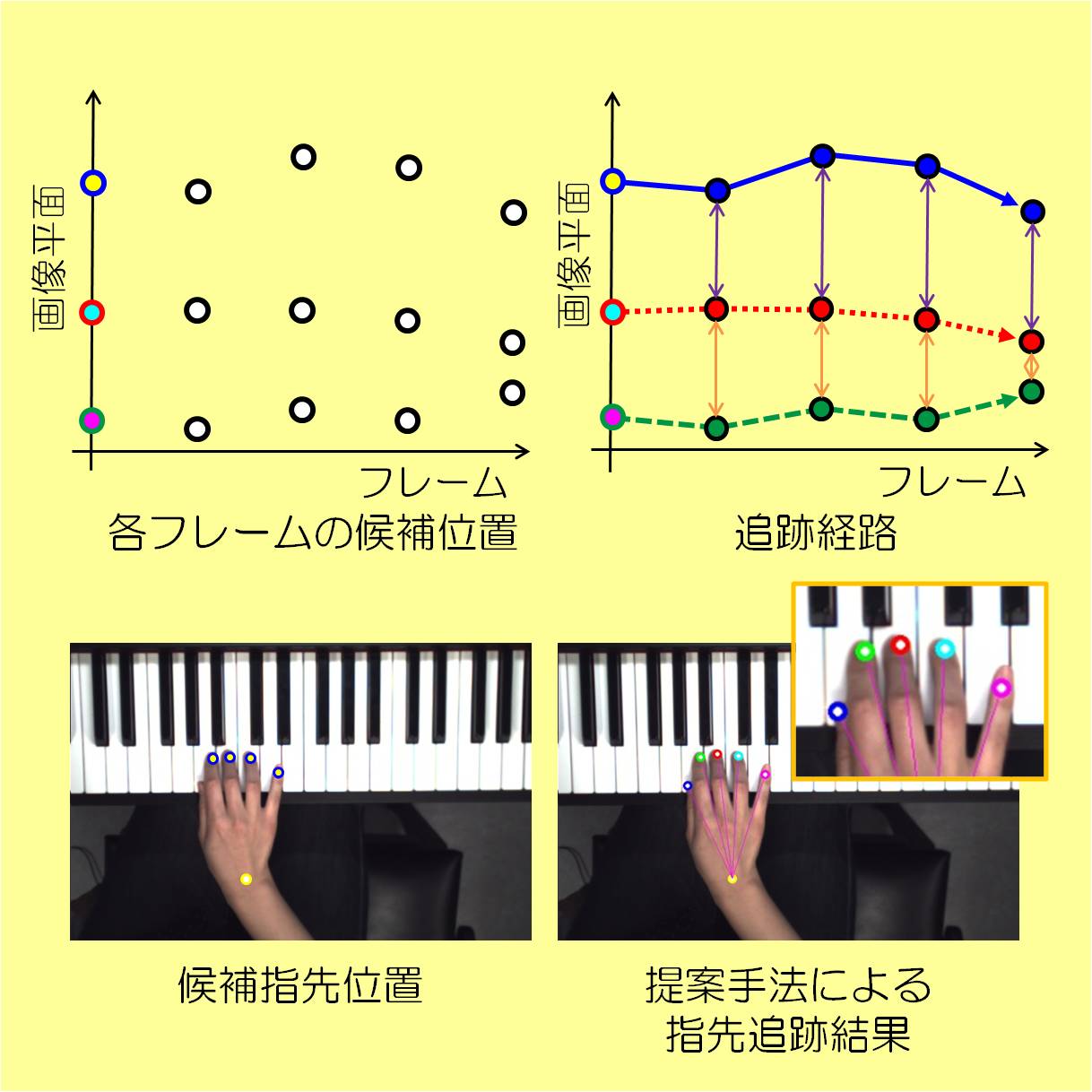
複数の移動パターンの位置を1つの状態パラメータとして定義し,物体間の相対的な位置関係を考慮した同時多点追跡手法を開発しました.
動画像中に映る複数物体を追跡する場合は,物体同士の類似性や物体の密着,セルフオクルージョンの発生によって追跡が不安定になるという問題があります.これらの問題を解決するために,本手法では物体間の相対的な位置関係を考慮した同時多点追跡を,離散的DPトラッキングと解析的DPトラッキングの2段階処理によって実現しました.各フレームで抽出した候補位置をもとに離散的DPトラッキングにより,粗い追跡経路を算出します.解析的DPトラッキングでは,この追跡経路を中心に局所コストを2次関数近似することにより,画像全体を探索空間として高精度な追跡を可能としました.
本手法を「指先パターン追跡」に応用し,ピアノ演奏スキル評価シ
ステムの 運指認識を実現しました.この技術はさまざまなユーザー
インターフェースに適用できます.
サブトラッカの最適配置に基づくオクルージョンに強い物体追跡
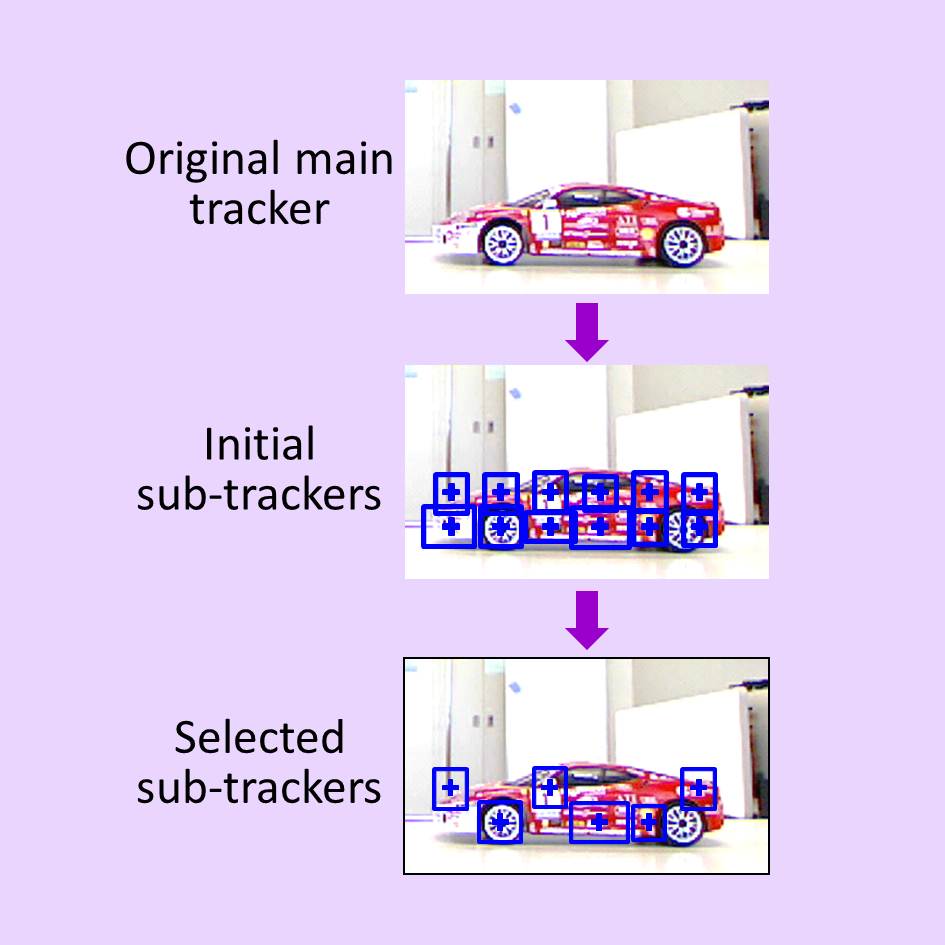
動画像からの物体追跡において,追跡対象が遮蔽物に隠されるオクルージョン問題を解決する新手法を提案しました.
対象物体(メイントラッカ)から複数の小領域(サブトラッカ)を自動設定し,サブトラッカごとのマッチング結果を統合して全体の推定をおこないます.この際,すべてのサブトラッカを同等に扱うのではなく,オクルージョンに対する頑健性が高くなるサブトラッカ群を選択します.本研究では,色ヒストグラムの独自性が周辺に対して高く,また一方向からのオクルージョンに対する影響が小さくなるサブトラッカ群を自動決定します.対象物の約 80% が隠されるような状況下でも,従来手法であるMeanShift法やパーティクルフィルタ法よりも頑健な性能を持つことを実証しました.走行する自動車のトラッキングなどに適しています.
SIFTキーポイントの効率的な削減アルゴリズム
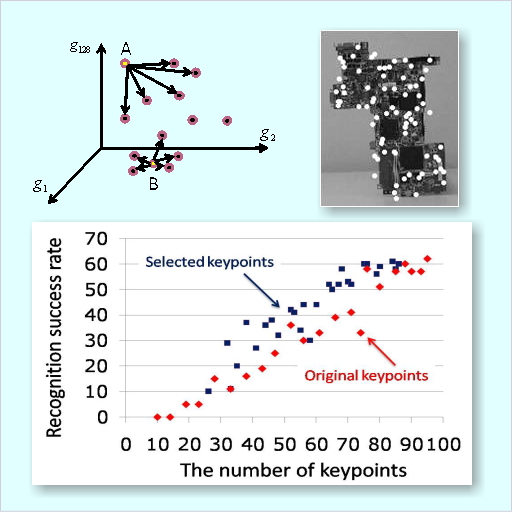
SIFT(Scale-Invariant Feature Transform)マッチングは,画像から検出したキーポイントと呼ばれる特徴点群を使って2枚の画像を照合する技術です.汎用性が高いことから多くの利用実績がありますが,キーポイント数が多い場合には処理に時間がかかるという問題点がありました.
本研究では,従来のSIFTアルゴリズムが使用しているキーポイントを分析し,マッチングのために有用なキーポイントを自動的に選択する手法を提案しました.その結果,従来よりも 10~20%程度キーポイント数を削減でき,さらにマッチング精度も向上することがわかりました.
これまでSIFTマッチングを使っていた分野だけでなく,ロボット視覚や対象物の追跡,人間の追跡,画像検索など幅広い用途に応用できます.