Last updated: Sep. 24, 2016.
【参考文献】
- 武井翔一,秋月秀一,橋本学“識別性能の予測に基づく選択的特徴量を用いたばら積み部品の認識”,精密工学会誌,Vol.81,No.4,pp.363-367,2015.
- 概要
本手法は,特徴量の有効性を識別性能として事前評価し, この性能が高い特徴量のみを照合に使用することによって,ばら積み物体を高信頼に認識します. 識別性能は,物体モデルと入力データの対応点における特徴量の安定性と, 正しい対応点以外から記述された偽の特徴量との分別性によって評価されます. このとき,3D-CGを用いて生成した入力データを使用することによって識別性能を予測します. そして,性能が高い特徴量を選択的に照合に使用することによって,高信頼な認識を実現します. - アルゴリズムの流れ
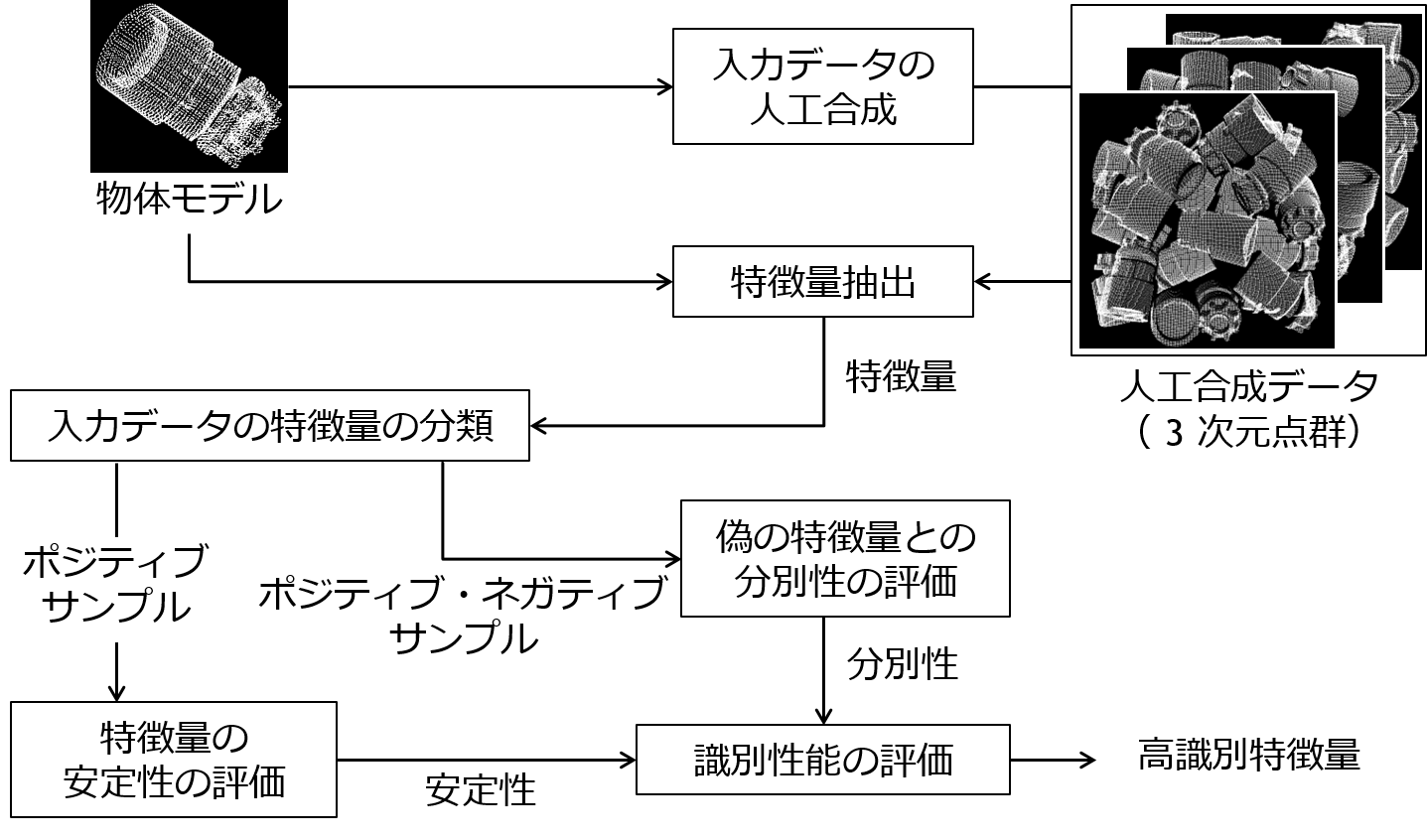
本手法では, まず,物理シミュレータと3D-CGを使用してばら積み物体で構成される入力データを 人工合成し,特徴量を抽出します. これによって,入力データに発生する特徴量を予測します. 次に,物体モデルから特徴量を一つ抽出し, ばら積み物体に発生する特徴量を2種類に分類します. 一つは,抽出した物体モデルの特徴量と正しく対応すべき特徴量であり, これをポジティブサンプルとします. もう一つは,ポジティブサンプル以外の特徴量であり, これをネガティブサンプルとします. そして,分類したポジティブ・ネガティブサンプルを用いて物体モデルの特徴量の安定性と偽の特徴量との分別性を算出し, これらを統合することによって識別性能を評価します. この識別性能は,物体モデルの全ての特徴量に対して評価し, 最終的に性能が高い複数の特徴量(高識別特徴量)を認識に使用します.
- 特徴量の安定性の評価
特徴量の安定性はポジティブサンプルの集中度合P+によって算出されます. ここで,ポジティブサンプル群を集合S+={s+i |i=1,2,…,N}とします. そして,識別性能の評価のために,式(1)を用いてポジティブサンプルの代表点x を生成します. P+はこのxを用いた式(2),(3)により評価されます.
P+はこのxを用いた式(2),(3)により評価されます.
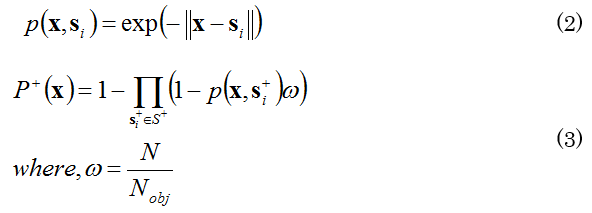
pはxと他のサンプル点siとの距離であり, 大きいほど特徴空間におけるxとsiの距離が近いことを意味します. また,式(3)におけるNobjは,ばら積みシーン中の物体数であり, ωはポジティブサンプルの検出率です. この式(3)におけるP+は大きいほどポジティブサンプル群が集中していることを意味します.
- 偽の特徴量との分別性の評価
偽の特徴量との分別性は, ポジティブサンプルとネガティブサンプルの分離度合P-により評価されます. ここで,ネガティブサンプル群をクラスタリングし, 生成したネガティブサンプルの代表点群を集合S-={s-i|i=1,2,…,M}とすると, P-は式(4)により計算されます.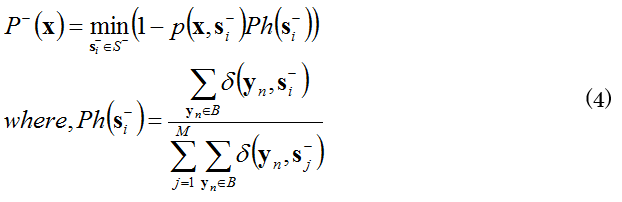 特徴空間上のネガティブサンプルをynとし,その集合をBとすると, δはynがネガティブサンプルの代表点s-iと同クラスであった場合に1を 出力する関数です.Phはs-i周辺のネガティブサンプルの発生頻度を 全ネガティブサンプル数で正規化することによって計算されます. そのため,Phはs-i周辺に発生するネガティブサンプル数が 多いほど高い値となります.したがって, P-は大きいほど発生頻度の高いネガティブサンプル群と分離していることを 意味します.
特徴空間上のネガティブサンプルをynとし,その集合をBとすると, δはynがネガティブサンプルの代表点s-iと同クラスであった場合に1を 出力する関数です.Phはs-i周辺のネガティブサンプルの発生頻度を 全ネガティブサンプル数で正規化することによって計算されます. そのため,Phはs-i周辺に発生するネガティブサンプル数が 多いほど高い値となります.したがって, P-は大きいほど発生頻度の高いネガティブサンプル群と分離していることを 意味します. - 識別性能の評価と高識別特徴量の選択
識別性能Rは,P+とP-を統合する式(5)によって評価されます. R値の高い特徴量は,P+とP-の両方が大きく, 特徴量の安定性と偽の特徴量との分別性が高いため, 本手法では,R値の高い複数の特徴量を事前に選択し, 使用することによって高信頼な認識を実現します.
R値の高い特徴量は,P+とP-の両方が大きく, 特徴量の安定性と偽の特徴量との分別性が高いため, 本手法では,R値の高い複数の特徴量を事前に選択し, 使用することによって高信頼な認識を実現します.
このページの制作: 橋本研究室(武井翔一) Copyright 2015 ISL, Chukyo University