Last updated: June 8, 2013.
- 概要
テンプレートマッチングはテンプレート画像を入力画像で走査させ,入力画像上の各位置における類似度を算出し, 最大(もしくは,しきい値以上)の類似度をとる位置を検出する手法です.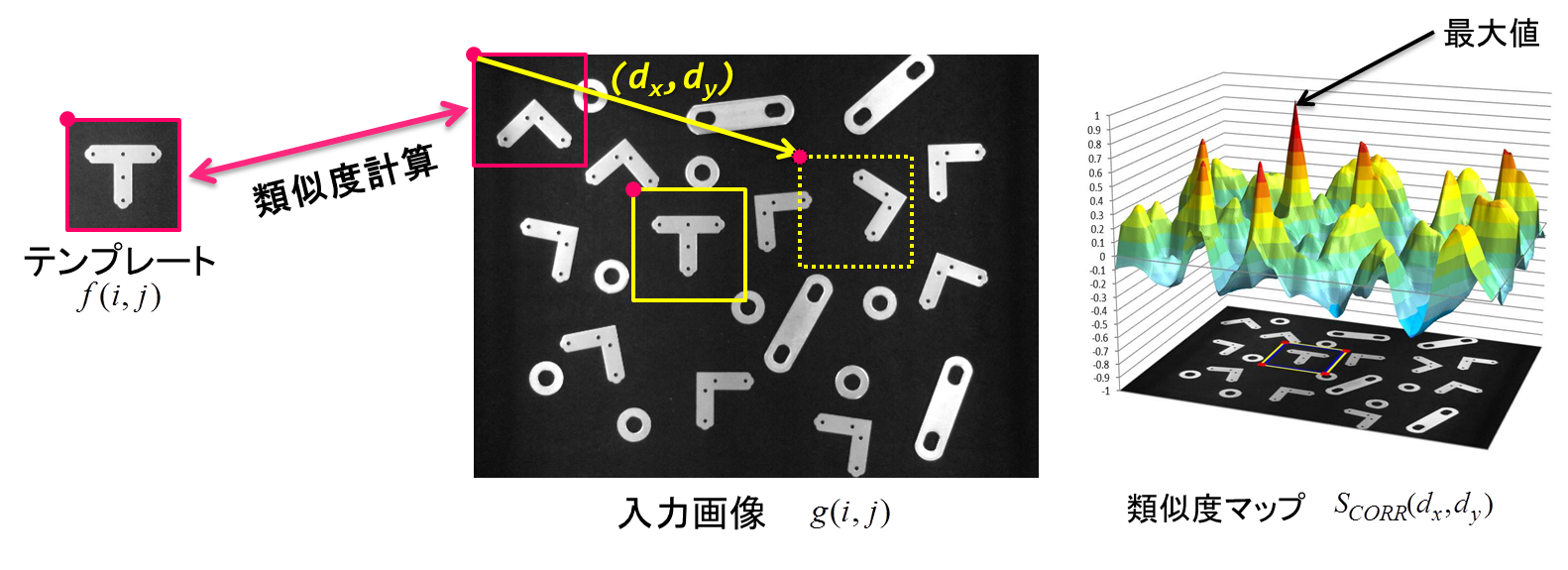
本ページではテンプレートマッチングの基本的な類似度指標である,Sum of Abusolute Difference(SAD), Sum of Squared Difference(SSD),Normalized Cross-Correlation(NCC), Zero-means Normalized Cross-Correlation(ZNCC)について解説します.
- Sum of Abusolute Difference(SAD),Sum of Squared Difference(SSD)
SADはテンプレートfと入力画像gの濃度値の差の絶対値和,SSDは差の2乗和です. 「各画素値の違いの量」の累積値なので,値が小さいほうが似ていることになります. SAD,SSDは以下の式によって算出できます. dx,dyは走査位置です.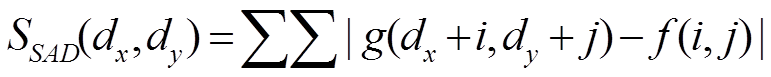
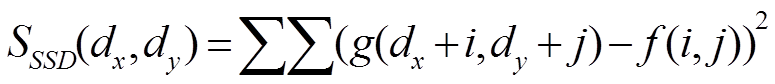
ただし,これらの類似度尺度では,画像の明るさ変動に対応することができません.
- Normalized Cross-Correlation(NCC)
NCCは画像のゲインの変動を吸収することができる類似度尺度です.NCCは以下の式によって計算できます.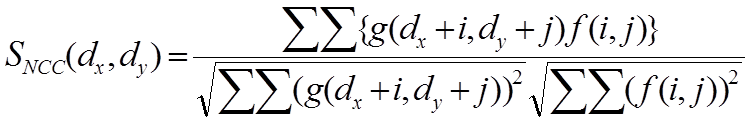
この式は内積の式と同一です. つまり,画像をベクトルとみなして内積を計算しています. これにより,NCC値はベクトルの長さ(ゲイン変動)の影響を受けません.
- Zero-means Normalized Cross-Correlation(ZNCC)
ZNCCでは,f,gをそれぞれ画像領域内の濃度値分布と考え,統計量としての相互相関係数を計算します.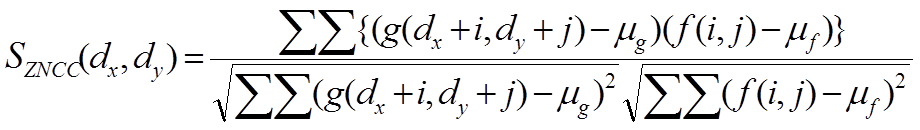
μf,μgは,f,gの平均値です. ZNCCはNCCと同じくゲインの変動を吸収することができる類似度尺度です. また,平均値を引いているので,2つの画像領域の平均値が異なっていても類似度が1になります(平均明るさ変動を吸収できる). 一般的には,NCCよりもZNCCのほうがよく使われます.
- ZNCCの計算の簡略化
上記のZNCCの式をそのままコーディングすると,平均値計算のために1回,ZNCC値の計算のためにもう1回の合計2回のループが必要となり, 計算効率が悪いです. そこで,ZNCCの構成は(fとgの共分散)/(fの標準偏差)(gの標準偏差)となっているので, よく知られた以下の公式[分散 = 標準偏差の2乗 = (データの2乗の平均値)―(データの平均値の2乗)] を使うことでループ処理を1回に削減できます.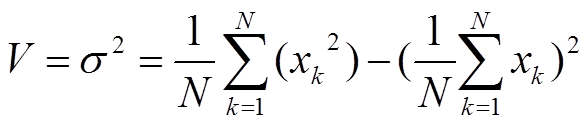
- 類似度尺度の計算量の比較
本ページで説明した類似度尺度の計算コストを比較しました. テンプレート画像を71×55[pixel],入力画像を600×400[pixel]とし, それぞれの類似度尺度で照合したときの処理時間を調べました. 実験に使用したシステムはCPU:Intel(R) CORE(TM)i7-2600K 3.4GHz,システムメモリ:32GB, OS:Windows7-64bitです.プログラムはC言語で作成し,Cygwinで動作させました. コンパイラはgcc ver.4.5.3,最適化オプション-O2を使用しました. SSE機能は使用していません.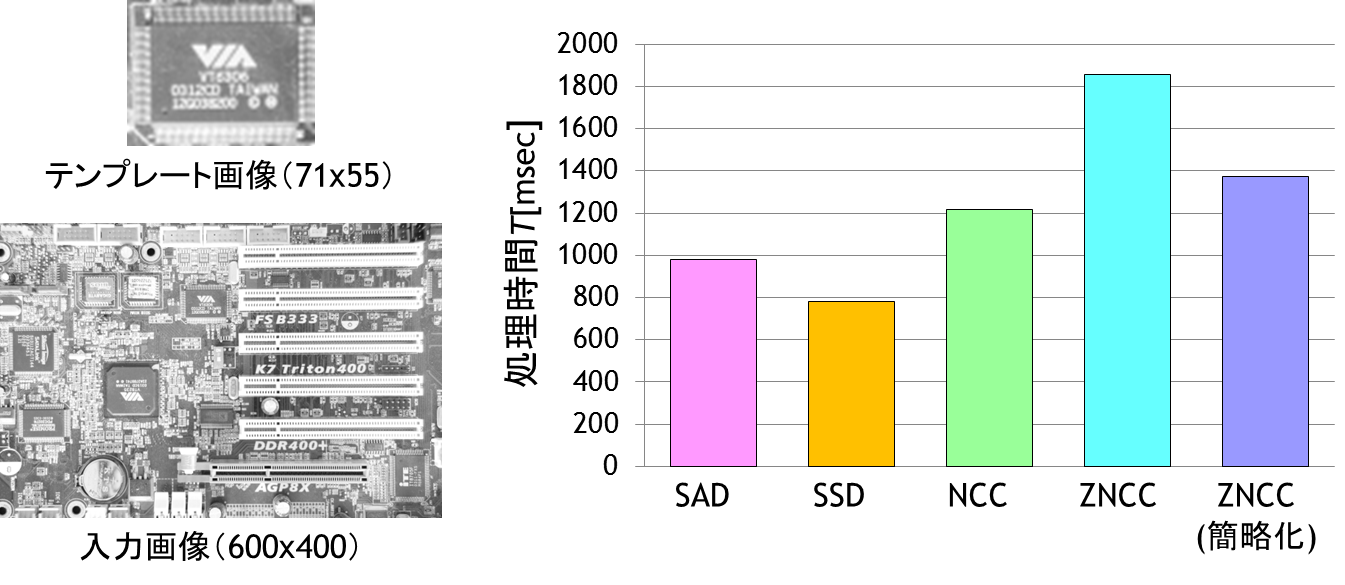
このページの制作: 橋本研究室(秋月秀一,櫻本泰憲) Copyright 2013 ISL, Chukyo University