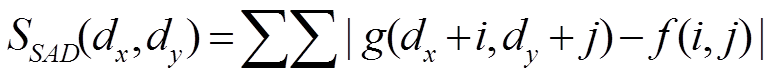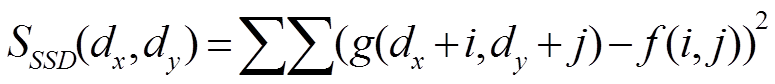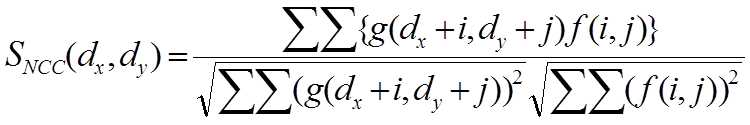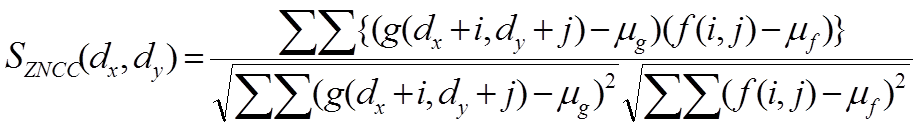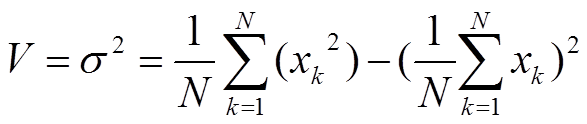※ アクセス制限ありEnglish ]
基本的なテンプレートマッチング
Last updated: June 8, 2013.
概要 Sum of Abusolute Difference(SAD),Sum of Squared Difference(SSD) f と入力画像g の濃度値の差の絶対値和,SSDは差の2乗和です.
「各画素値の違いの量」の累積値なので,値が小さいほうが似ていることになります.
SAD,SSDは以下の式によって算出できます.
dx ,dy は走査位置です.Normalized Cross-Correlation(NCC) Zero-means Normalized Cross-Correlation(ZNCC) f ,g をそれぞれ画像領域内の濃度値分布と考え,統計量としての相互相関係数を計算します.μf ,μg は,f ,g の平均値です.
ZNCCはNCCと同じくゲインの変動を吸収することができる類似度尺度です.
また,平均値を引いているので,2つの画像領域の平均値が異なっていても類似度が1になります(平均明るさ変動を吸収できる).
一般的には,NCCよりもZNCCのほうがよく使われます.ZNCCの計算の簡略化 f とg の共分散)/(f の標準偏差)(g の標準偏差)となっているので,
よく知られた以下の公式[分散 = 標準偏差の2乗 = (データの2乗の平均値)―(データの平均値の2乗)]
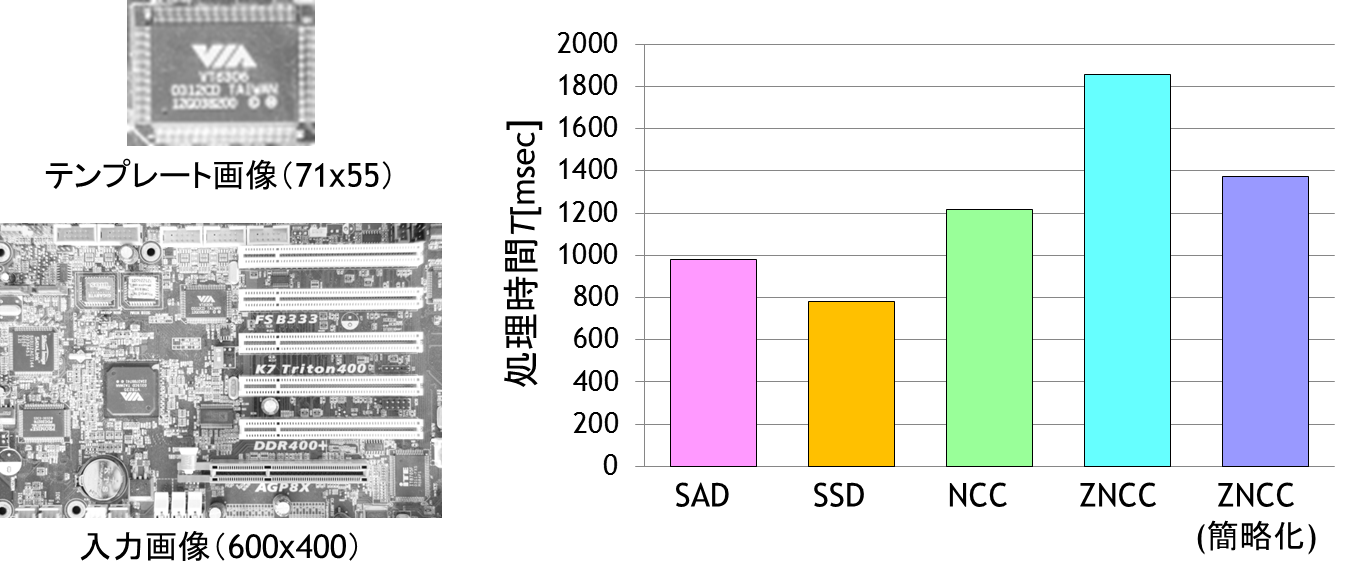
を使うことでループ処理を1回に削減できます.類似度尺度の計算量の比較
このページの制作: 橋本研究室(秋月秀一,櫻本泰憲) Copyright 2013 ISL, Chukyo University
▲Topへ