TSCI:Time-Series Cooking Image Dataset
– Overview
This dataset was created for the purpose of monitoring the state of ingredients during the cooking process. It consists of time-series cooking images paired with corresponding recipe texts. Using this dataset, a Vision–Language Model (VLM) can train the relationship between cooking images and recipe texts. In addition, it enables the evaluation of existing models’ performance in cooking-task monitoring. As a basic usage guideline, the data in the train directory is intended to be used for training and validation, while the data in the test directory should be used for evaluation.
When you use this dataset in publications such as conference papers or journal articles, please cite the following URL or reference.
URL: http://isl.sist.chukyo-u.ac.jp/archives/tsci
<Reference>
Rina Tagami, Hiroki Kobayashi, Shuichi Akizuki, Manabu Hashimoto, Food State Recognition from Recipes Using Multimodal Model for Task Monitoring in Autonomous Cooking Robots, In Scandinavian Conference on Image Analysis 2025 (SCIA2025), vol.15726, pp.356-369, Reykjavik, Iceland, 2025/06/23.
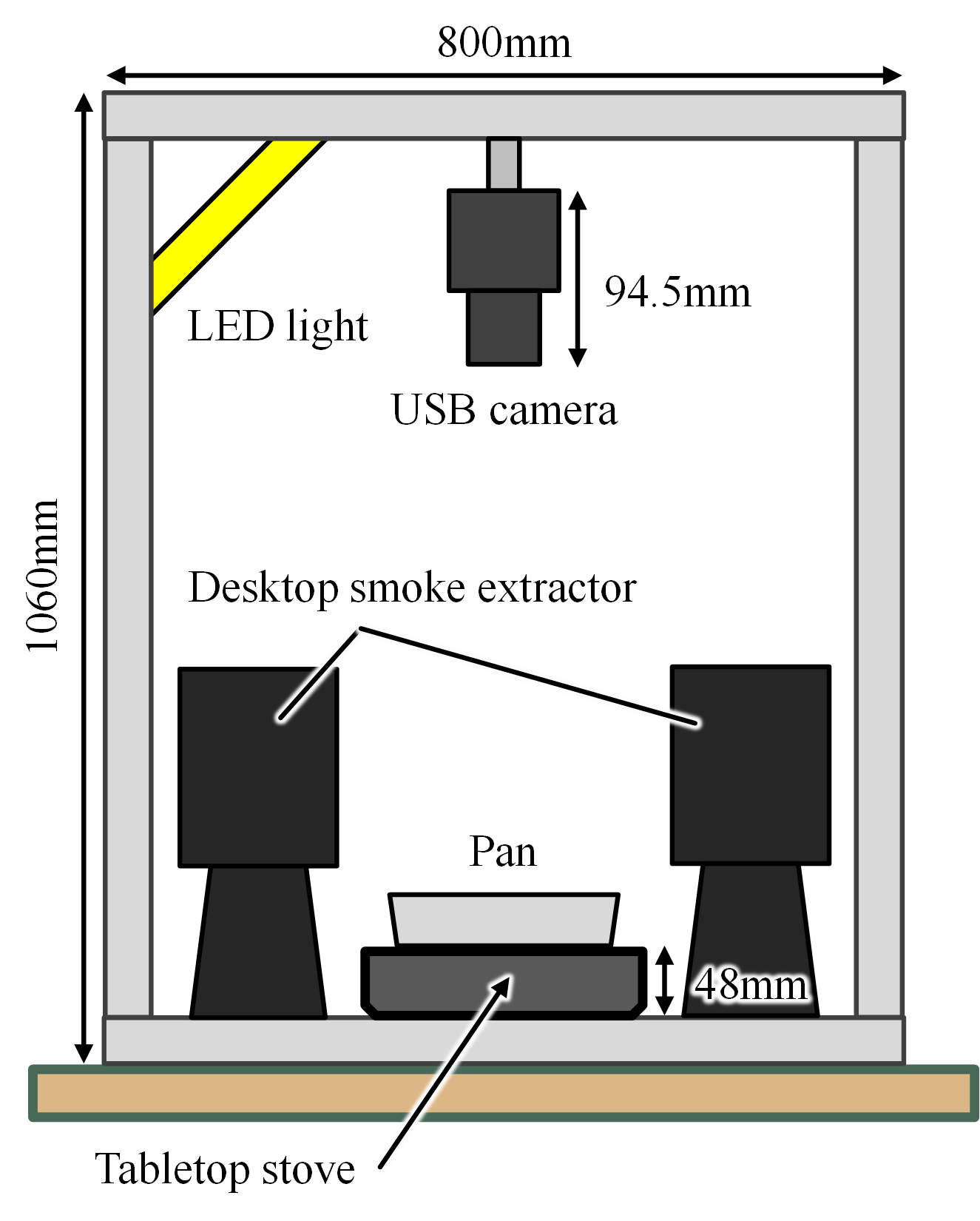
– How to collect data
This dataset was constructed using a specialized image acquisition setup. An overview of the recording environment is shown in the figure below.
– Released Data
This dataset was constructed from videos captured under the aforementioned recording setup (30 fps, 1280 x 720 resolution, 3-color channels). Each video was divided into individual frames, which were then trimmed and resized before being released. During frame extraction, all frames were extracted and saved as sequential PNG images. For each image, the region defined by the top-left coordinate (325, 45) and bottom-right coordinate (955, 675) was cropped, and the resulting image was resized to 244 x 244 pixels using bilinear interpolation. The cooking scenes in the videos were performed according to a set of prepared recipe texts. Each frame was paired with its corresponding recipe text, and this annotation was manually performed by the person who actually conducted the cooking.
<Download: Overhead Cooking Task Monitoring dataset>
■Dataset information: TSCI_info.tar.gz
■Sunny-side-up
 ■Train data(10 videos, total 170,760 image-text pairs, 19.2GB)
■Train data(10 videos, total 170,760 image-text pairs, 19.2GB)
:
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
[20]
[21]
■Test data(4 videos, total 66,888 image-text pairs, 7.3GB)
:
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
■Onion
 ■Train data(10 videos, total 165,930 image-text pairs, 17.2GB)
■Train data(10 videos, total 165,930 image-text pairs, 17.2GB)
:
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
■Test data(2 videos, total 20,640 image-text pairs, 2.2GB)
:
[1]
[2]
[3]
■Caramel sauce
 ■Train data(10 videos, total 129,024 image-text pairs, 13.7GB)
■Train data(10 videos, total 129,024 image-text pairs, 13.7GB)
:
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
■Test data(2 videos, total 36,082 image-text pairs, 3.7GB)
:
[1]
[2]
[3]
[4]
■Pancake
 ■Train data(10 videos, total 44,838 image-text pairs, 4.5GB)
■Train data(10 videos, total 44,838 image-text pairs, 4.5GB)
:
[1]
[2]
[3]
[4]
[5]
■Test data(5 videos, total 18,612 image-text pairs, 1.9GB)
:
[1]
[2]
- How to unzip file
Please replace
1. Combine the tar.gz parts
cat <dataset>_part_*.tar.gz > <dataset>.tar.gz
2. Extract the tar.gz file
tar -xvzf <dataset>.tar.gz
- Directory Structure
datasets
|--TSCI_info
| |--train.json
| |--test.json
|--TSCI_egg_train
| |--egg_video001
| | |--GT.txt
| | |--frames
| | |--00000.png
| | |--00001.png
|--TSCI_egg_test
|--TSCI_onion_train
|--TSCI_onion_test
|--TSCI_caramel_train
|--TSCI_caramel_test
|--TSCI_pancake_train
|--TSCI_pancake_test
The dataset contains the information and several cooking videos categorized as follows:
Information(TSCI_info), Sunny-side-up videos (TSCI_egg_train, TSCI_egg_test), Onion videos (TSCI_onion_train, TSCI_onion_test), Caramel sauce videos (TSCI_caramel_train, TSCI_caramel_test), Pancake videos (TSCI_pancake_train, TSCI_pancake_test).
Each video directory contains a sequence of frame images (frames) and a file named “GT.txt” lists the recipe text associated with each frame. In addition, the files “train.json” and “test.json” summarize information about all classes, including recipe texts, frame indices, and class labels. These JSON files can be used to efficiently load data during model training.